!! 결과화면이 검은색 -> Series, 아니고 표 -> DataFrame
Groupwise analysis
value_counts()와 같은 기능을 하도록 groupby()를 응용해보겠습니다.

value_count()함수의 축약형이라 봐도 무방합니다.
point() column을 콕 집어서 각 원소가 몇 개씩 들어있는지 보는 거죠.
df.groupby('col_name').col_name.count()
== reviews.groupby('points').size()

grouping한 결과에 summary function을 사용해도 됩니다.
각 점수마다 가장 싼 와인을 보기 위해, 'points' column으로 grouping 한 뒤 price column의 값으로 계산했습니다.

여러 개의 group들은 만든다면, 거의 datafame을 slicing한 꼴이 됩니다. 대신, Series처럼 data와 value, 일대일 대응으로 말이죠.
Dataframe의 apply() 함수로, 보기 좋게 조정할 수 있습니다. 예로 각 양조장에서 첫 번째로 리뷰해준 와인의 이름을 고르는 방법입니다.

agg( ) 함수를 groupby()에 적용했습니다. 이는 서로 다른 여러 함수를 dataframe에 동시에 적용시켜줍니다.
옆의 예시는 길이, 최솟값, 최대값을 계산하여 간단한 통계 요약본을 출력하는 방법입니다.
groupby()는 한 개가 아닌 여러 개의 column도 사용 가능합니다.
다음 코드는 국가와 지방에서 가장 최고로 꼽히는 와인을 뽑는 방법입니다.
groupby()안에 원하는 column의 이름들만 들어있는 리스트 한 개를 넣어줍니다.

Multi-indexes
지금까지 single-label index로 된 Series 또는 Dataframe만 다뤘습니다.
사실 groupby()로 multi-index로 불리는 결과를 산출한다면, 위의 둘과는 다른 Data Object랍니다.
그런 결과를 산출하는 방법을 다뤄봅시다.
먼저 multi-index는 multiple levels(다층적)인 개념을 갖기에 일반 index와는 다릅니다.

Multi-index만의 (단일index가 아닌) 복잡한 구조를 다루기 위한 몇가지 함수들이 있습니다.
값을 검색하려면 두 계층 이상의 label이 필요합니다 (country, province -> 2개)
Multi-index 관련 Pandas 사용법 은 여기를 참고하세요.

일반적으로 자주 사용하는 함수는, single-index로 다시 변환하는 reset_index() 함수입니다,
Sorting
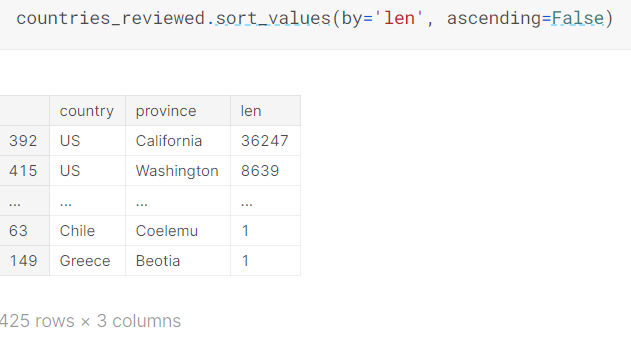
국가와 지방 별 리뷰를 담아둔 'countries_reviewed' Multi-index를 single-index로 바꿔보겠습니다.
주목해야할 점은 groupby()를 사용하면, value 순서가 아닌 "" index "" 순서로 반환된다는 점입니다.
즉, group별 결과를 출력할 때 row의 순서는 데이터가 아닌 index의 값에 좌우된다는 점입니다.
그러한 순서를 얻기 위해, sort_values() 함수는 사용합시다.
기본값은 오름차순이며, 오른쪽 코드(ascending=False)는 내림차순으로 정렬하는 방법입니다.
맨 아래 사진은, 한 번에 1개 이상의 column에 대해 정렬하는 방법입니다.
리스트 하나 속에 원하는 column이름을 적어줍니다.
 |
 |
 |

index의 value를 정렬하려면, sort_index() 함수를 사용합니다.
index가 179가 아닌 0부터 시작하여 오름차순으로 정렬되었습니다.
Exercise
Q1. 주어진 돈으로 살 수 있는 최고의 와인을 찾기 위한 Series 생성하기

price는 오름차순으로 정렬(4.0~3300.0달러)할 때,
해당 가격대의 와인 중 가장 높은 point가 담긴 Series를 생성
Q2. 각 와인의 종류('variety')에 따라 최고, 최소 가격을 담은 DataFrame 생성하기

index가 vareity,
column, 즉 그에 대한 각각의 index가 가지는 값들은 min, max 값.
Q3. 가장 비싼 와인 종류 알아보기.

Q2에서 만든 dataframe을 이용하여
min과 max column을
내림차순으로 정렬해보세요.
Q3. taster(맛 감정가)마다 평균 평점이 어떤지에 대한 Series 생성하기


평균: .mean()
describe()함수를 이용해보면,
19명의 taster가 있었군요.
대부분의 taster는 아마도 88점을 줄 것입니다.
평균도, 중간값도 88점이니까.
아무리 적어도 85점을 주고, 높아봐야 90점이네요.
아무리 낮아봐야 85, 높아봐야 90, 평균적으로 90점이라...
각각의 값들이 크게 차이나지 않으니,
해당 dataframe에서 유의미한 차이를 얻기는 힘들 것 같네요.
Q4. 국적과 와인 종류를 조합해보았을 때 어느 것이 가장 흔한 지 봅시다
마지막 사진을 보시면 US에서 생산한 Pinot Noir 종이 9885개로 가장 흔하군요.

{country, variety} 쌍으로 된 MultiIndex를,
index로 가지는 Series를 생성합시다.
(2 종류의 index가 하나의 index처럼 구별됨)

해당 Series를
내림차순으로
'Machine Learning > [Kaggle Course] Data Visualization' 카테고리의 다른 글
| [Kaggle Course] Renaming & Combining (row, col) (0) | 2020.11.26 |
|---|---|
| [Kaggle Course] Data Types, Missing Values, Replace - Dtype (0) | 2020.11.26 |
| [Kaggle Course] Summary Functions and Maps (0) | 2020.11.19 |
| [Kaggle Course] Indexing, Selecting & Assigning (0) | 2020.11.18 |
| [Kaggle Course] Creating, Reading and Saving (0) | 2020.11.18 |