1. Key-indexing by Dictionary of Python

오른쪽 하단 사진을 보면 알다시피, |
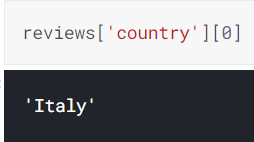  |
2. Indexing in Pandas
iloc~ index
- dataset을 여러개의 리스트, 즉 큰 matrix로 다루어야할 때 사용,
- 해당 값의 인덱스 위치 값을 알 때 사용,
- 차이점: python stdlib indexing scheme을 사용하므로, 0:10을 넣으면 0~9까지 총 10개만.
loc~Categorical of float numbers
- column_name(indices)를 이용하여 값에 접근
- 차이점: 0:10을 넣으면 0~10 총 11개를 선택함. 이름으로 접근하니깐.
2-1. Index-based selection
.iloc[idx_row, idx_column]
 슬라이싱 가능 |
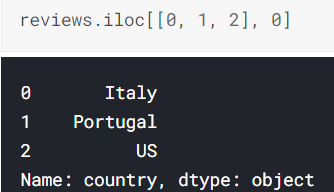 슬라이싱 말고도 list를 넣어도 됨. |
 음수 인덱싱으로 뒤에서부터 참조가능. .tail()가 같은 기능 |
 원래 하던 대로 0번째를 가져올 수야 있지만 pandas를 좀 더 응용해본다면 .iloc[0]을 쓰는 법을 습관화 해두자 |
+) first row만 가져오고 싶다면
first_row = reviews.iloc[0,:]+) review의 description에서 처음 10개의 row를 출력하고 싶다면
reviews.description.iloc[:10] #way1
reviews.description.head(10) #way2
reviews.loc[:9, "description"] #way3
2-2. Label-based selection
.loc[name/num_of_row, name_of_column]
label로 이루어진 index를 다룰 때 유용. 그러나 index는 바꿀 수 없다는 성질을 갖고 있기에, 그럴 땐 -> go 3

+) review의 description에서 처음 10개의 row를 출력하고 싶다면
reviews.description.head(10) #way1
reviews.loc[:9, "description"] #way2
#reviews dataset의 row index가 우연처럼 0부터 시작한다는 점이 iloc과 일치하여 햇갈릴 수 있으니 주의+) 원하는 row만 뽑아오고 싶을 때 - 현재는 1, 2, 3, 5, 8 row만 가져오려함 -> 리스트로 감싸기 필수!
sample_reviews = reviews.loc[[1,2,3,5,8]]
+) 원하는 column과 row를 뽑아오고 싶을 때 -> 새로운 DataFrame으로 다뤄볼 수 있다!!

3. Manipulating the index
.set_index(row_index_name)
ex) .set_index("title") _ "title"이란 이름의 row_index를 추가해줌.
index의 immutable한 성질에 대한 보완책

4. Conditional selection _ with .loc[ ]
True/False가 되는 조건문 loc[ ]에 넣으면 원하는 값만 group으로 모아서 추출 가능
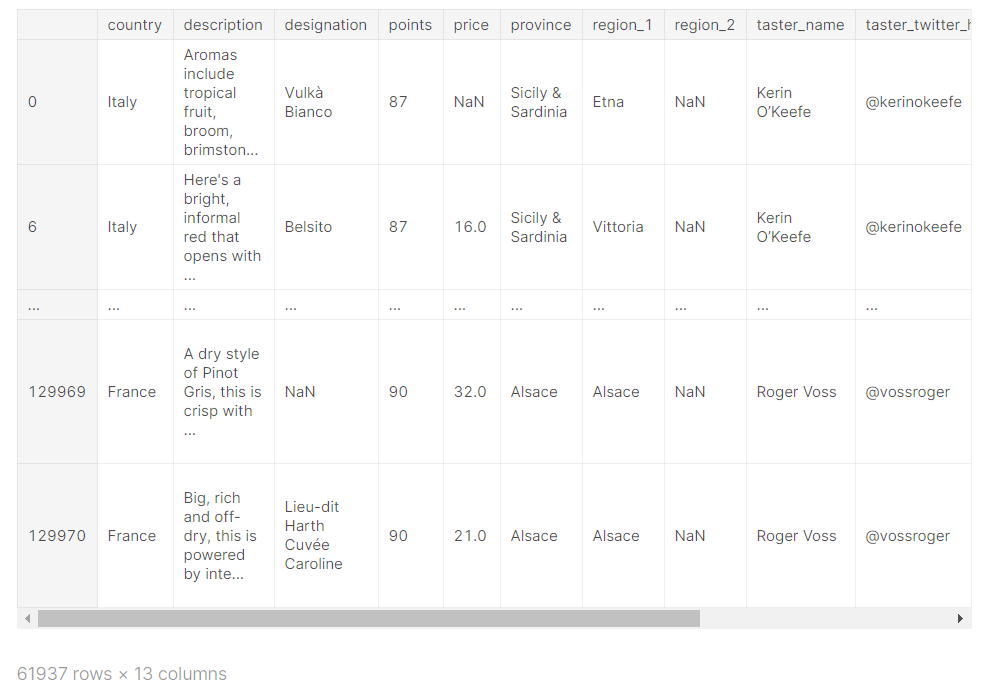
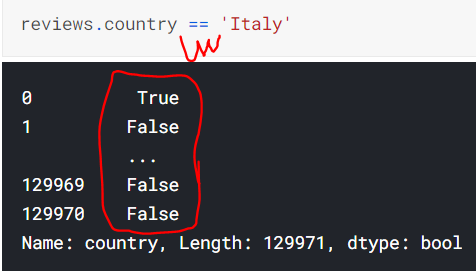 1번의 표의 왼쪽 사진과 위의 사진을 비교해보세요. 그저 데이터를 뽑아오는 것뿐만 아니라 |
 |
- & 연산자로 두 질문을 한 번에 검사할 수 있음
reviews.loc[(reviews.country == 'Italy') & (reviews.points >= 90)]
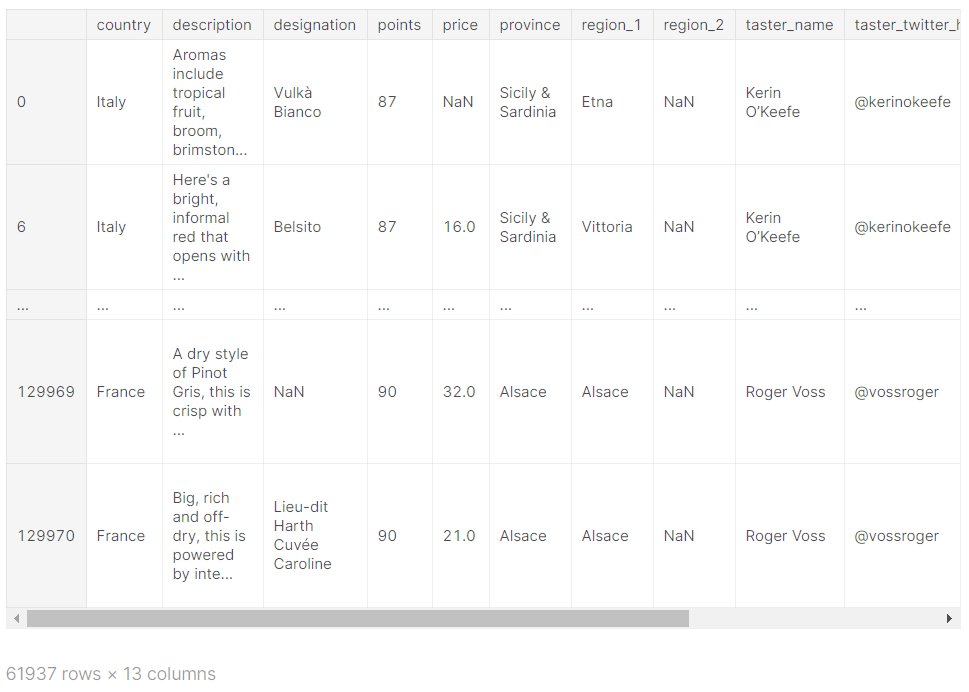
- | 연산자로 두 질문을 한 번에 검사할 수 있음
OR이다 보니 점수 좋은 France와인도 몇 개 생겼군.
reviews.loc[(reviews.country == 'Italy') | (reviews.points >= 90)]
4-1. Conditional selectors Built-in Pandas
- .isin()
리스트 안의 원소 중 단 하나라도 일치한다면 해당 row을 모아서 반환
하나만 해도 됨. 바로 아래의 코드 블럭은 위의 reviews.country == 'Italy'와 같은 결과가 나오는 코드
italian_wines = reviews.loc[(reviews.country.isin(['Italy']))]밑의 예시는 이탈리아와 프랑스산 와인만 골라보는 코드 -> 여러 개도 한 번에 가능
reviews.loc[reviews.country.isin(['Italy', 'France'])]
5. Assigning data to DataFrame
 해당 column의 모든 값을 "everyone"으로 바꾸게 됨 |
 해당 column에 반복대상(리스트, range() 등등)와 같은 것을 넣어주면 차례대로 값이 입력됨. |
Exercise

'country'와 'variety' column에서
처음 100개의 row를 뽑아 df에 저장하는 방법
way1 - loc은 entry의 value에 대한 것이므로 [:100]와 같은 slicing은 인식되지 않음.
그러니, [ ] 필요없이 그저 :99(시작:마지막)을 적어야 함을 유의하자
df = reviews.loc[:99, ['country', 'variety']]way2 - 그래서 0~99개의 숫자를 가진 리스트를 생성하려면 아래와 같이 해주어도 됨.
df = reviews.loc[[i for i in range(100)],['country','variety']]way3 - iloc을 쓰고 싶다면 위의 column들의 각각의 index를 알고 있다면 가능
iloc은 python slicing처럼 마지막 값은 제외시키는 점 주의
df = reviews.iloc[:100, [0,11]]
문제2
Australia 또는 New Zealand에서 생산된 와인 중 최소 95점 이상 받은 와인을
top_oceania_wines라는 이름을 가지는 dataFrame 생성하기
top_oceania_wines = reviews.loc[(reviews.points >= 95) & reviews.country.isin(["Australia","New Zealand"]) ]
'Machine Learning > [Kaggle Course] Data Visualization' 카테고리의 다른 글
| [Kaggle Course] Grouping and Sorting - groupby() (0) | 2020.11.26 |
|---|---|
| [Kaggle Course] Summary Functions and Maps (0) | 2020.11.19 |
| [Kaggle Course] Creating, Reading and Saving (0) | 2020.11.18 |
| Certificate - Data Visualization (0) | 2020.11.18 |
| [Kaggle Course] Add data on myNoteBook + (Download/Upload data on Kaggle) (0) | 2020.11.18 |