728x90
반응형
import pandas as pd
1. Creating data
이제부터 DataFrame과 Series에 대해서 알아보겠습니다. 이 둘은 긴밀히 연관되어 있습니다.
Series 여러 개를 붙혀서 한 다발로 만들면 DataFrame이 된다고 생각해도 좋습니다.
Type 1. DataFrame == Table
- 각 cell(entry)마다 특정한 값을 가지는 배열
- pd.DataFrame() 생성자로 DataFrame 객체를 만듦
- 딕셔너리를 입력. key == column_name, value == list_type (element of the list will be a each entry's value)
- row label은 자동적으로 index가 되어 0부터 시작.
- 'index' parameter를 생성자에 넣어주면 다른 값들을 index로 쓸 수 있음.


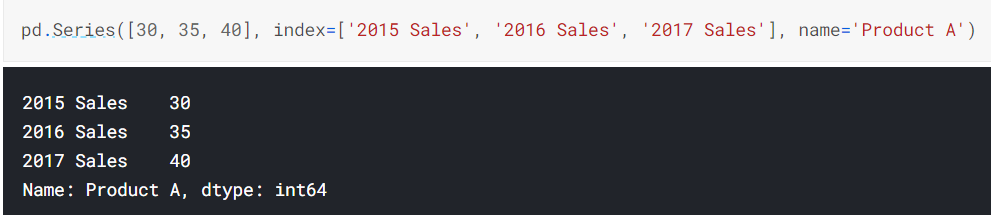
Type 2. Series == List
- A sequence of data values
- 사실은, list를 그대로 사용해도 되긴해요.
- 그 관점으로 본다면, Series는 DataFrame의 a column입니다.
- 'index' parameter를 사용하여 row_label을 지정한 것처럼,
- 동일한 방식으로, 해당 column의 값을 Series에 저장할 수 있습니다.
- 그러나 Series에는 column 이름은 저장할 수 없으며, 오직 전체 이름(변수이름)만 가집니다.
2. Reading data files
보통 CSV 파일이 많은데요. 이는 Comma-Separated Values의 약자입니다.
해당 타입의 파일을 읽는 방법은 다음과 같습니다.
wine_reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv", index_col = 0)
wine_reviews.shape # returns (len(row), len(column))
wine_reviews.head()DataFrame에 shape 필드 변수를 적용하면 data의 크기에 대해 알 수 있습니다.
>>> return (몇 개의 기록이 들어있는지, 이들이 몇 개의 column으로 나누어졌는지)
괄호 안의 두 숫자를 곱하면 해당 dataset의 총 entries 수가 나오겠네요.
더불어 항상 파일 내용을 조사하기 전에는 .head()를 꼭 써서 봅시다.
pd.read_csv()에는 30개의 parameter가 존재합니다.
pandas가 처음부터 새로운 column을 만드는 대신,
해당 column을 index으로 쓰게 하려면 'index_col' parameter로 지정합니다.
3. Save data(DataFrame) file to CSV
animals = pd.DataFrame({'Cows': [12, 20], 'Goats': [22, 19]}, index=['Year 1', 'Year 2'])
animals.to_csv("cows_and_goats.csv")
Exercise



728x90
반응형
'Machine Learning > [Kaggle Course] Data Visualization' 카테고리의 다른 글
| [Kaggle Course] Summary Functions and Maps (0) | 2020.11.19 |
|---|---|
| [Kaggle Course] Indexing, Selecting & Assigning (0) | 2020.11.18 |
| Certificate - Data Visualization (0) | 2020.11.18 |
| [Kaggle Course] Add data on myNoteBook + (Download/Upload data on Kaggle) (0) | 2020.11.18 |
| [Kaggle Course] Choosing Plot Types and Custom Styles (0) | 2020.11.16 |