1. Sumary functions
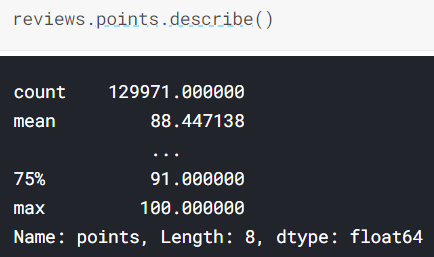
- .describe() - 주어진 column의 특성을 요약
 |
 |
- .mean() - numerical value로 구성된 column의 평균

- .median() - numerical value로 구성된 column의 중앙값

- .unique() - 해당 column에 들어있는 모든 값을, 수에 상관없이 하나씩, list 형식으로 모아서
어떤 회사/국가만 데이터에 입력되어 있는지 확인할 때 유용.

- .value_counts() - 내림차순으로 각 value가 몇 개씩 들어있는지 반환
와인을 마신 사람마다 몇 개의 리뷰를 달았는지, row를 가지는지 확인할 때 유용

2. Maps and Apply
'Map'이란 수학에서 가져온 용어로, 하나의 집합을 가져오는 함수를 의미합니다. 그걸 다른 집합에 일일이 적용하죠.
기존의 데이터를 재해석하여 새로운 데이터로 만들 때, data format을 전체적으로 바꿔야 할 때 씁니다.
- df.column_name.map(함수이름)
간단한 함수라면 lambda를 써도 됩니다.
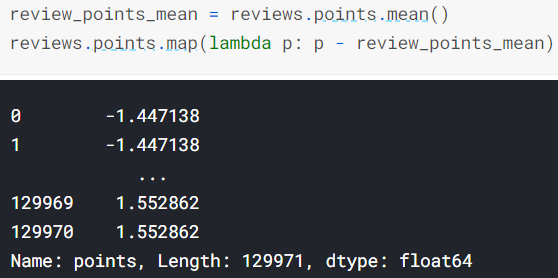 pandas가 자동적으로 해주니 오른쪽처럼 꼭 map 사용X 괜춘 |
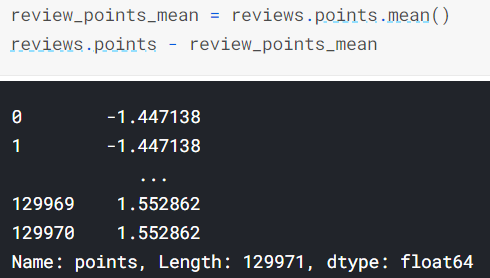 - 3번 참고 |
- df.apply(함수이름, axis='')

내가 만든 함수를 (parameter와 reuturn는 row or column)
각 row마다 -> axis = 'columns'
각 column마다 -> axis = 'index'
적용하여 전체 dataframe을 변형시키고 싶을 때 사용합니다.
apply에 사용한 함수의 return 값을 row나 column이 아닌, 그저 변수(숫자,문자,불린) 등으로 할 경우,
Dataframe 타입이 아닌 Series 타입이 됩니다.
이 글의 마지막 문제 3번을 참고하세요.
3. Mapping operations built-in Pandas
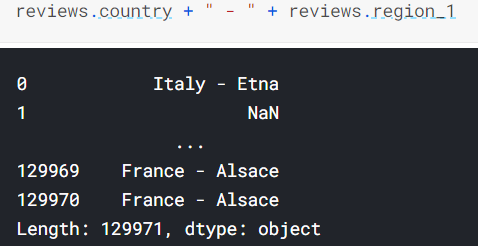
왼쪽에 위치한 반복대상에,
알아서 오른쪽의 연산을 각 value마다 일일히 적용해줌
아래의 예시는 국가와 지역을 ' - ' 문자로 이어주는 작업을 country column의 모든 entry에 적용한 결과
Exercise
1. points/price 비율에서 가장 높은 마진을 얻을 수 있는 와인의 이름을 구하시오.
hint) .idxmax()
bargain_idx = (reviews.points / reviews.price).idxmax()
bargain_wine = reviews.loc[bargain_idx, 'title']
2. description column에 'tropical' 또는 'fruity'라고 평가된 와인의 수를 가진 Series를 생성하시오.

hint) map()으로 각 entry마다 'tropical' 여부 확인 후, 참이면 count에 1씩 증가시키세요.
'fruity'도 마찬가지로. 마지막에는 Series를 만들어서 두 값을 결합시켜보세요.
n_trop = reviews.description.map(lambda desc: "tropical" in desc).sum()
n_fruity = reviews.description.map(lambda desc: "fruity" in desc).sum()
descriptor_counts = pd.Series([n_trop, n_fruity], index=['tropical', 'fruity'])
3. 현재 dataset의 rating system은 80 ~ 100 사이 값입니다. 이는 다른 이들이 보기에 다 좋은 것처럼 보일 수 있죠. 그래서 star rating system을 도입하고자 합니다. 95점 이상이면 3 stas, 최소 85점 이상 95점 미만이면 2 stars, 그 외 1 star.
여기에 Canada 산 와인은 무조건 3 stars를 주세요. 캐나다에서 후원받고 있어서 어쩔 수 없습니다.

그럼 각 리뷰마다 star의 개수가 담긴 Series를 생성하세요.
def stars(row):
if row.country == 'Canada' or row.points >= 95:
return 3
elif row.points >= 85:
return 2
else:
return 1
star_ratings = reviews.apply(stars, axis='columns')
'Machine Learning > [Kaggle Course] Data Visualization' 카테고리의 다른 글
| [Kaggle Course] Data Types, Missing Values, Replace - Dtype (0) | 2020.11.26 |
|---|---|
| [Kaggle Course] Grouping and Sorting - groupby() (0) | 2020.11.26 |
| [Kaggle Course] Indexing, Selecting & Assigning (0) | 2020.11.18 |
| [Kaggle Course] Creating, Reading and Saving (0) | 2020.11.18 |
| Certificate - Data Visualization (0) | 2020.11.18 |