Simple to Refined
지난 세 수업에서 convnet이 feature extraction을 수행하는 과정을 보았습니다.
그 과정은 filter, detect, condense 연산을 차례대로 거쳐가는 것입니다.
feature extraction의 한 라운드는 단순한 선이나 대비와 같은 이미지에서 비교적 간단한 feature만 추출할 수 있습니다.
수많은 분류 문제를 해결하기에 너무 간단하죠.
대신에 convnets은 이러한 추출과정을 여러번 반복합니다.
그로 인해 feature는 좀 더 복잡해지고, 더 깊은 네트워크를 여행하며 정교해집니다.

Convolutional Blocks
추출을 해주는 convolutional block들의 긴 사슬을 통과하면서 진행됩니다.
convolutional block 사슬은 Conv2D와 MaxPool2D 레이어를 여러 개 쌓아서 만들어졌으며 feature extraction를 수행합니다.

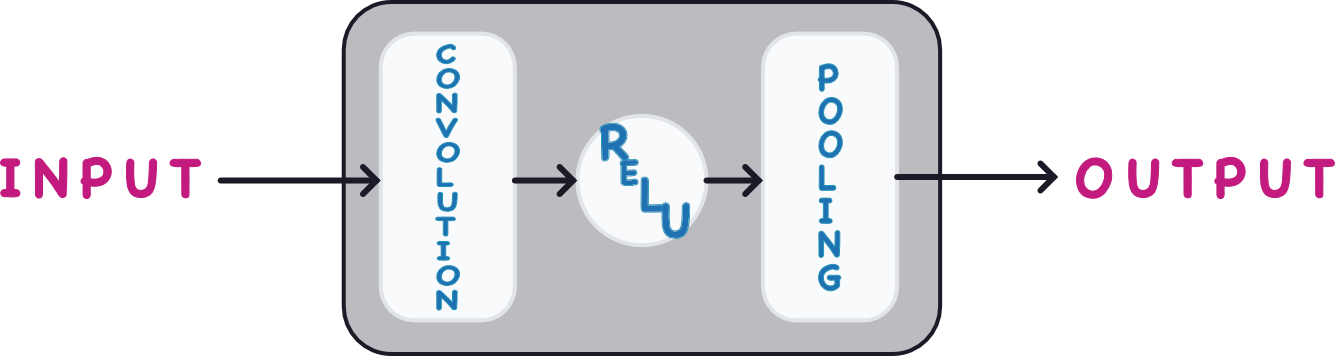
각각의 블록은 한 라운드의 추출을 지칭하며 이러한 block을 구성함으로써 convnet은 feature를 결합 또는 재결합할 수 있습니다. 또한 그 블록들을 더 키우거나 모양을 다르게 하여 해당 문제에 더욱더 적합하게 만들 수 있습니다.
현대 convnet의 깊은 구조는 복잡한 feature engineering을 다룰 수 있게 되었습니다.
Example - Design a Convnet
복잡한 features를 다룰 수 있는 Deep convolutional network를 정의하는 방법을 봅시다.
이번엔 Keras의 Sequence 모델을 사용하여 Cars 데이터셋을 이용해 훈련할 것입니다.
1. Load Data
# Imports
import os, warnings
import matplotlib.pyplot as plt
from matplotlib import gridspec
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing import image_dataset_from_directory
# Reproducability
def set_seed(seed=31415):
np.random.seed(seed)
tf.random.set_seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
os.environ['TF_DETERMINISTIC_OPS'] = '1'
set_seed()
# Set Matplotlib defaults
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
plt.rc('image', cmap='magma')
warnings.filterwarnings("ignore") # to clean up output cells
# Load training and validation sets
ds_train_ = image_dataset_from_directory(
'../input/car-or-truck/train',
labels='inferred',
label_mode='binary',
image_size=[128, 128],
interpolation='nearest',
batch_size=64,
shuffle=True,
)
ds_valid_ = image_dataset_from_directory(
'../input/car-or-truck/valid',
labels='inferred',
label_mode='binary',
image_size=[128, 128],
interpolation='nearest',
batch_size=64,
shuffle=False,
)
# Data Pipeline
def convert_to_float(image, label):
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
return image, label
AUTOTUNE = tf.data.experimental.AUTOTUNE
ds_train = (
ds_train_
.map(convert_to_float)
.cache()
.prefetch(buffer_size=AUTOTUNE)
)
ds_valid = (
ds_valid_
.map(convert_to_float)
.cache()
.prefetch(buffer_size=AUTOTUNE)
)Found 5117 files belonging to 2 classes.
Found 5051 files belonging to 2 classes.
2. Define Model
이번에 사용할 모델의 도표입니다.
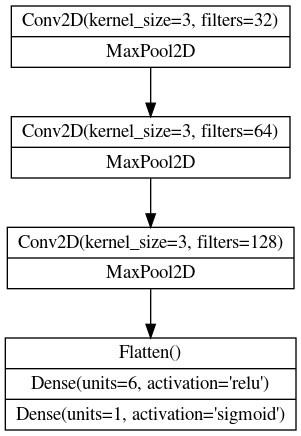
사용할 모델은 3개의 블록으로 구성되어있습니다.
Conv2D와 MaxPool2D 레이어(base) 그 후에 dense 레이어(head)로요.
이 도표를 Keras의 Sequentail 모델에 맞게 해석하겠습니다.
적합한 매개변수를 채우는 식으로요.
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
# First Convolutional Block
layers.Conv2D(filters=32, kernel_size=5, activation="relu", padding='same',
# give the input dimensions in the first layer
# [height, width, color channels(RGB)]
input_shape=[128, 128, 3]),
layers.MaxPool2D(),
# Second Convolutional Block
layers.Conv2D(filters=64, kernel_size=3, activation="relu", padding='same'),
layers.MaxPool2D(),
# Third Convolutional Block
layers.Conv2D(filters=128, kernel_size=3, activation="relu", padding='same'),
layers.MaxPool2D(),
# Classifier Head
layers.Flatten(),
layers.Dense(units=6, activation="relu"),
layers.Dense(units=1, activation="sigmoid"),
])
model.summary()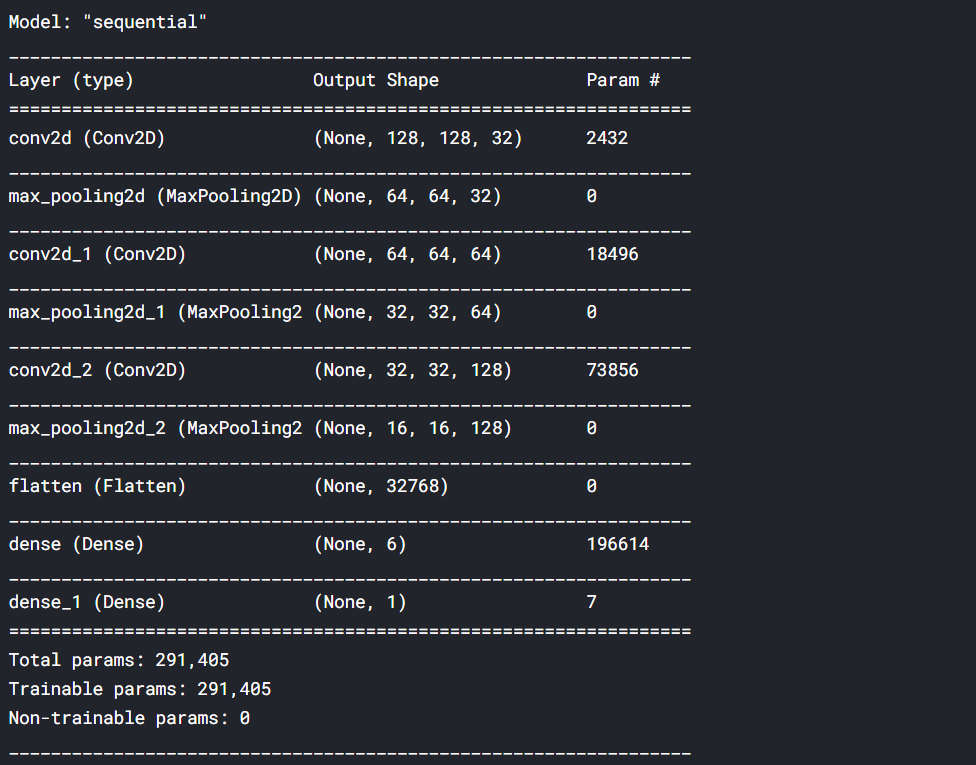
여기서 주목해야할 것은 어떻게 필터 수가 블록 단위로 두 배씩 증가했는지 보는 것입니다 (64, 128, 256)
이는 흔한 패턴입니다. MaxPool2D 레이어는 feature maps의 크기를 줄이기 때문에 생성해야하는 양을 늘릴 여유가 생깁니다.
3. Train
이 모델을 첫번째 수업 때처럼 훈련시켜보려 합니다.
이진 분류에 적합한 loss와 metric에 따라서 모델을 최적화기(optimizer)로 컴파일 합시다.
model.compile(
optimizer=tf.keras.optimizers.Adam(epsilon=0.01),
loss='binary_crossentropy',
metrics=['binary_accuracy']
)
history = model.fit(
ds_train,
validation_data=ds_valid,
epochs=40,
verbose=0,
)import pandas as pd
history_frame = pd.DataFrame(history.history)
history_frame.loc[:, ['loss', 'val_loss']].plot()
history_frame.loc[:, ['binary_accuracy', 'val_binary_accuracy']].plot();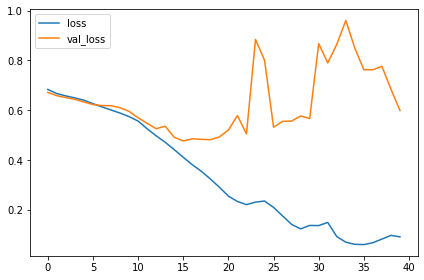 |
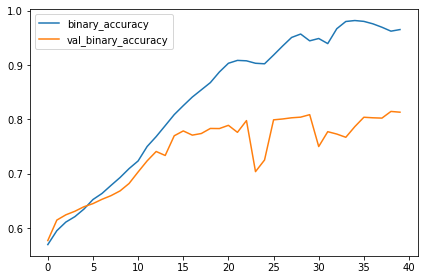 |
이 모델은 VGG모델보다 훨씬 작습니다. VGG는 16개의 convolutional 레이어가 필요하지만 이 모델은 오직 3개면 됩니다. 그럼에도 이 데이터셋에 상당히 잘 맞습니다.
convolutional 레이어를 추가함으로써 간단한 모델을 향상시킬 수 있습니다.
그럼 데이터셋에 더욱 적합한 features를 생성할 수 있습니다.
이 과정을 지금 해보려 합니다.
Exercise
1차시 수업에 사용한 VGG16 모델과 성능을 비교해가며 자신만의 convnet을 만들어봅시다
# Setup feedback system
from learntools.core import binder
binder.bind(globals())
from learntools.computer_vision.ex5 import *
# Imports
import os, warnings
import matplotlib.pyplot as plt
from matplotlib import gridspec
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing import image_dataset_from_directory
# Reproducability
def set_seed(seed=31415):
np.random.seed(seed)
tf.random.set_seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
os.environ['TF_DETERMINISTIC_OPS'] = '1'
set_seed()
# Set Matplotlib defaults
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
plt.rc('image', cmap='magma')
warnings.filterwarnings("ignore") # to clean up output cells
# Load training and validation sets
ds_train_ = image_dataset_from_directory(
'../input/car-or-truck/train',
labels='inferred',
label_mode='binary',
image_size=[128, 128],
interpolation='nearest',
batch_size=64,
shuffle=True,
)
ds_valid_ = image_dataset_from_directory(
'../input/car-or-truck/valid',
labels='inferred',
label_mode='binary',
image_size=[128, 128],
interpolation='nearest',
batch_size=64,
shuffle=False,
)
# Data Pipeline
def convert_to_float(image, label):
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
return image, label
AUTOTUNE = tf.data.experimental.AUTOTUNE
ds_train = (
ds_train_
.map(convert_to_float)
.cache()
.prefetch(buffer_size=AUTOTUNE)
)
ds_valid = (
ds_valid_
.map(convert_to_float)
.cache()
.prefetch(buffer_size=AUTOTUNE)
)
Found 5117 files belonging to 2 classes.
Found 5051 files belonging to 2 classes.
Design a Convnet
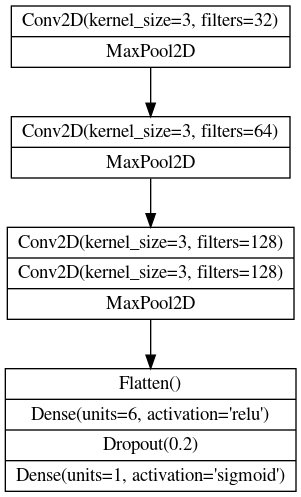
block 구조의 convolutional network를 설계해봅시다.
3개의 블록을 가지고 각 블록은 하나의 convolutional layer를 가지고 있습니다.
Car or Truck 데이터셋에서의 성능 좋았지만 VGG16에서 했을 때와 비교하면 성능이 떨어집니다.
그 이유는 이 간단한 네트워크 복잡한 features를 추출할 능력이 부족하기 때문입니다.
이 모델의 성능을 향상시키기 위해 블록을 추가하거나 블록에 convolution을 추가해보려 합니다.
그 이후에는 두번째 블록 속의 Conv2D 레이어의 수를 2로, 세번째 블록은 3으로 늘립니다.
1. Define Model
도표에 따라 세개의 블록으로 구성된 레이어를 정의하여 모델을 완성합시다.
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
# Block One
layers.Conv2D(filters=32, kernel_size=3, activation='relu', padding='same',
input_shape=[128, 128, 3]),
layers.MaxPool2D(),
# Block Two
layers.Conv2D(filters=64, kernel_size=3, activation='relu', padding='same'),
layers.MaxPool2D(),
# Block Three
# YOUR CODE HERE
layers.Conv2D(filters=128, kernel_size=3, activation='relu', padding='same'),
layers.Conv2D(filters=128, kernel_size=3, activation='relu', padding='same'),
layers.MaxPool2D(),
# Head
layers.Flatten(),
layers.Dense(6, activation='relu'),
layers.Dropout(0.2),
layers.Dense(1, activation='sigmoid'),
])
2. Compile
훈련을 준비하기 위해 모델에 Car or Truck 데이터셋에 적절한 loss와 accuracy metric를 컴파일합시다.
Car or Truck 데이터셋에 적절하려면 이진 분류와 관련있는 걸로 선택해야 합니다.
model.compile(
optimizer=tf.keras.optimizers.Adam(epsilon=0.01),
# YOUR CODE HERE: Add loss and metric
loss='binary_crossentropy',
metrics=['binary_accuracy'],
)마지막으로 새로운 모델의 성능을 테스트 해봅시다
먼저 하단의 코드를 실행하여 trainding set을 model에 맞춰봅니다.
history = model.fit(
ds_train,
validation_data=ds_valid,
epochs=50,
)

이후에는 훈련이 되는 동안의 loss와 metric 곡선을 그래프로 그려봅시다.
import pandas as pd
history_frame = pd.DataFrame(history.history)
history_frame.loc[:, ['loss', 'val_loss']].plot()
history_frame.loc[:, ['binary_accuracy', 'val_binary_accuracy']].plot();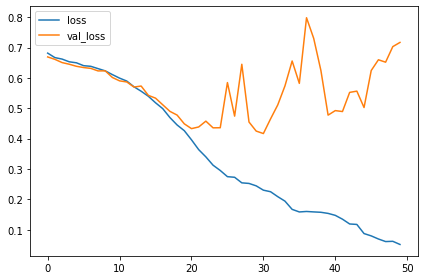 |
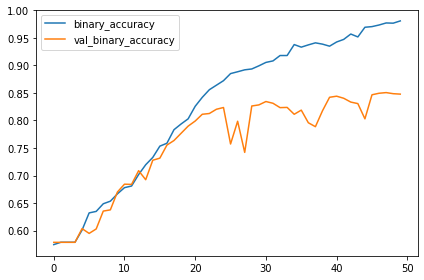 |
3. Train the Model
training 곡선이 어떤가요? 이 모델은 이전 모델보다 좋은가요?
이전 모델의 learning curves는 빠르게 갈라졌습니다. 이는 과적합이며 regularization(정규화)가 필요합니다.
새 모델에 추가한 레이어는 더욱더 과적합이 되도록하였습니다.
그러나 Dropout 레이어와 함게 몇가지 정규화를 거친다면 이를 예방할 수 있습니다.
이러한 변화들은 몇 가지 포인트 지점들에 의해 모델의 validation 정확도를 향샹시킬 수 있습니다.
Conclusion
이번 시간에는 나만의 convnet을 만들어서 특정 분류 문제를 풀었습니다.
요즘의 대부분의 모델은 이미 훈련된 base 위에서 만들어짐에도 불구하고, 어떤 상황에서는 더 작은 custom convnet이 나을 수 있습니다.
예로 더 작거나 흔하지 않은 dataset을 이용한다거나, 매우 한정된 자원에서 계산해야하는 경우죠.
보셨다시피 특정 문제에서 이들은 이미 훈련된 모델만큼 수행을 잘 할 수 있습니다.
'Machine Learning > [Kaggle Course] ML (+ 딥러닝, 컴퓨터비전)' 카테고리의 다른 글
| [생활코딩/CNN] Flatten (0) | 2021.07.20 |
|---|---|
| Data Augmentation - boost classifier (0) | 2021.04.12 |
| The Sliding Window (0) | 2021.04.10 |
| Maximum Pooling - feature extraction (0) | 2021.04.09 |
| Convolution and ReLU (0) | 2021.04.03 |