728x90
반응형
기초 코드
###########################
# 라이브러리 사용
import tensorflow as tf
import pandas as pd###########################
# with reshape
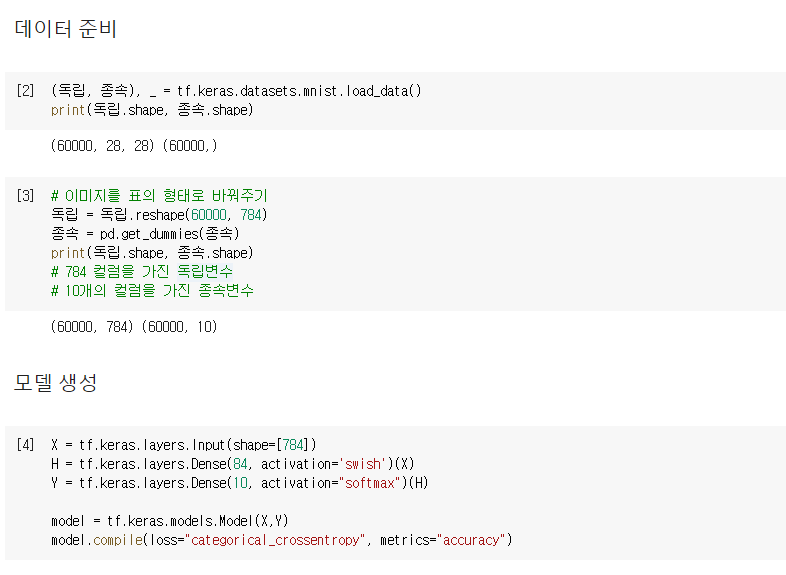
# 데이터를 준비
(독립, 종속), _ = tf.keras.datasets.mnist.load_data()
#(60000,28,28) -> (60000,784)
독립 = 독립.reshape(60000, 784) # 전체 육만장의 데이터를 784의 컬럼을 가진 표의 형태로 변환
종속 = pd.get_dummies(종속)
print(독립.shape, 종속.shape)
# 모델의 구조 만들기
X = tf.keras.layers.Input(shape=[784]) # 독립변수x 컬럼 784개
H = tf.keras.layers.Dense(84, activation='swish')(X)
Y = tf.keras.layers.Dense(10, activation='softmax')(H) # 종속변수y 10개
model = tf.keras.models.Model(X, Y)
model.compile(loss='categorical_crossentropy', metrics='accuracy')
# 데이터로 모델을 학습(FIT)
model.fit(독립, 종속, epochs=10)
# 모델을 이용
pred = model.predict(독립[0:5])
print(pd.DataFrame(pred).round(2))
print(종속[0:5])
칼럼 = 변수 = 특징
칼럼 중, 즉 특징 중 가장 좋은 특징들을 추려내는 것이 목표
가중치를 통과하며 계산된 값을 통해 추려냄
히든 레이어에서,
가중치가 높다는 것은
해당 픽셀 값이 중요하다는 의미
가중치가 낮다는 것은
해당 픽셀 값이 무의미하다는 의미


Flatten
reshape 대신 사용하기에 reshape 삭제
입력의 모양과 flatten layer를 기억하자
x 데이터를 한 줄로 펴주는 기능
###########################
# with flatten
# 데이터를 준비하고
(독립, 종속), _ = tf.keras.datasets.mnist.load_data()
# 독립 = 독립.reshape(60000, 784)
종속 = pd.get_dummies(종속)
print(독립.shape, 종속.shape)
# (60000, 28, 28), (60000, 1)
# 모델을 만들고
X = tf.keras.layers.Input(shape=[28, 28]) #784에서 28, 28
# flatten은 reshpae에 해당하는 기능을 모델 내에서 수행
H = tf.keras.layers.Flatten()(X)
H = tf.keras.layers.Dense(84, activation='swish')(H)
Y = tf.keras.layers.Dense(10, activation='softmax')(H)
model = tf.keras.models.Model(X, Y)
model.compile(loss='categorical_crossentropy', metrics='accuracy')
# 모델을 학습하고
model.fit(독립, 종속, epochs=10)
# 모델을 이용합니다.
pred = model.predict(독립[0:5])
print(pd.DataFrame(pred).round(2))
print(종속[0:5])

728x90
반응형
'Machine Learning > [Kaggle Course] ML (+ 딥러닝, 컴퓨터비전)' 카테고리의 다른 글
| [생활코딩/CNN] MaxPool2D (0) | 2021.07.29 |
|---|---|
| [생활코딩/CNN] Conv2D (0) | 2021.07.28 |
| Data Augmentation - boost classifier (0) | 2021.04.12 |
| Custom Convnets (Convolutional Blocks) (0) | 2021.04.10 |
| The Sliding Window (0) | 2021.04.10 |