descriptive pattern
- association : ( similar relation) - (병의) 원인 감지용으로 사용, 추천시스템이나
- cluster : 전염병 감지 등..
Association Rules

연결 규칙에는 연결된 모집단(population)이 있어야 합니다
모집단은 인스턴스(instance) 집합으로 구성됩니다
예로 상점에서 각 거래 내역은 instance입니다
모든 거래의 집합은 population입니다
-
“support” : 규칙의 antecedent와 consequent 둘 다 만족하는 부분집합의 비율에 대한 척도
ex) 모든 구매의 0.001%만이 milk와 screwdrivers를 포함한다고 가정하자.
milk->screwdrivers 규칙에 대한 support는 낮음.
“confidence” : antecedent=True일 때 consequent=True인 비율에 대한 척도
ex) rule bread -> milk는 80%의 신뢰도를 가진다. 빵이 포함된 구매의 비율에는 우유도 포함한다.
How to find association rules
high support ( 2% 이상의 support)를 만족하는 association rules에 관심이 있다고 가정하고…
<Naive algorithm>
- 가능한 모든 서로쌍을 나열 (n items면 2^n itemsets)
- 각 서로쌍마다 support를 구함 (각 거래마다 얼마나 물건을 구매했는지 그 수량)
- Large itemsets : high support를 만족하는 집합
- large itemsets를 이용하여 association rule 생성
- A itemset로부터 rule (A- {b}) => b 생성 (이 때 각 b는 A 집합에 속한다)
- 여기서 A-{b}는 antecedent, b는 consequent
- Support of Rule = support(A)
- = (antecedent + consequence)
- confidence of rule = support(A) / support(A-{b})
- = (antecedent + consequence) / antecedent
- A itemset로부터 rule (A- {b}) => b 생성 (이 때 각 b는 A 집합에 속한다)
items 0,1,2에 대해
2^n개의 itemset 생성
만약 support s6이 가장 높다면
A = {0,2}, b는 A의 원소
이 때 b=0이라면
rule A-{b} => b 는
{2}=>{0}이 된다
이 때 b=2이라면
rule A-{b} => b 는
{0}=>{2}이 된다
그럼 support(A)는
{2}=>{0}, {0}=>{2} 모두 가능
이 둘은 same support 를 가지게 됨
그러나 confidence는 다름
모집단이 다음과 같다고 할 때
A = {0,2}이므로
support = support({0,2})
전체 5개 중 {0,2}를 모두 가진 집합은 1개 - {0,2,3}
support = 1/5
(support 결과가 2% 넘으면 됨. 1/5면 20%니 아주 좋은 것)
b=0 일 때
confidence = support({0,2}) / support({2})
2를 포함하는 집합의 개수는 3개 - {0,2,3}, {1,2}, {2,5}
confidence = (1/5)/(3/5) = 1/3 (33%)
b=2 일 때
confidence = support({0,2}) / support({0})
0을 포함하는 집합의 개수는 2개 - {0,2,3}, {0,1,5,10}
confidence = (1/5)/(2/5) = 1/2 (50%)
b=2 일때의 confidence가 b=0일 때보다 높으므로
{0}=>{2}이 true일 확률이 높음
Finding Support
모집단을 한 번만 훑어보며 support 결정하자
(Large itemsets : high support를 만족하는 집합)
그런데 memory에서 모든 itemset에 대해 multiple passes를 진행하기 버거울 때
각 pass마다 몇개의 itemset만 남겨두고 나머지는 제거하는 최적화를 거치자
제거되는 itemset은 상대적으로 나타날 빈도가 적은 것들이라 제거해도 상관 없음
priori 기법 : large itemset 찾기
2가 이전에 제거되면 2개짜리 itemset에서 2를 제외하고 만들면 되니까!
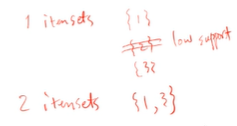

Clustering
centroid : point defined by taking average of coordinates in each dimension
할당된 그룹의 중심에서 점의 평균 거리가 최소화되도록 점을 k 집합으로 그룹화합니다(주어진 k에 대해).
아니면 군집의 모든 점 쌍 사이의 평균 거리 최소화하는 방식을 씀
Hierarchical clustering
- Agglomerative clustering algorithm : bottom-up
- Divisive clustering algorithm : top-down
Collaborative Filtering
목표: 그 사람의 과거 관심사와 사람들의 관심사를 바탕으로 moive/books/.. 중 어느 것에 관심 있는지 예측하기
repeated clustring에 기반하여 접근
movie 관심사에 따라 사람들을 클러스터링한다다.
그리고 같은 cluster의 사람들이 좋아하는 영화를 기반으로 영화를 clustering한다.
(새로 생성된 cluster인) movie에 대한 관심사에 따라 사람들을 다시 clustering한다.
equilibrium 상태가 될 때까지 위 과정을 반복한다.
새로운 user가 주어지면
기존에 존재하는 user cluster 중 가장 비슷한 쪽을 찾은 뒤
해당 user cluster에서 널리 사용되는 movie cluster의 movies를 예측
Other Types of Mining
- Text mining
- Setiment analysis : 댓글 속 긍정/부정 예측
- Information extraction : 비정형 텍스트 설명 또는 표와 같은 반정형 데이터에서 구조화된 정보 작성
- Entity recognition and disambiguation : ex) "Michael Jordan"는 유명한 농구 선수나 ML 전문가 중 누구를 가리킵니까?
- Knowledge graph : 위키피디아와 같은 다양한 출처에서 정보를 추출하여 구성할 수 있다. ( 위키피디아의 링크들로 그래프 생성)
'Web > DB & Cloud' 카테고리의 다른 글
| [GitMind] ERD tool - Mac에서 설치하기 (0) | 2021.12.29 |
|---|---|
| Information Retrieval (정보 검색) (0) | 2021.12.10 |
| Data Mining - prediction mechanism (0) | 2021.12.10 |
| Data Warehouse (0) | 2021.12.10 |
| OLAP : Online Analytical Processing (0) | 2021.12.10 |