repository (archive) of information
gathered from multiple sources,
stored under a unified schema,
at a single site
다양한 곳에서 값을 가져오지만 내부에서 행해지기에 transaction 과정이 필요하지 않음
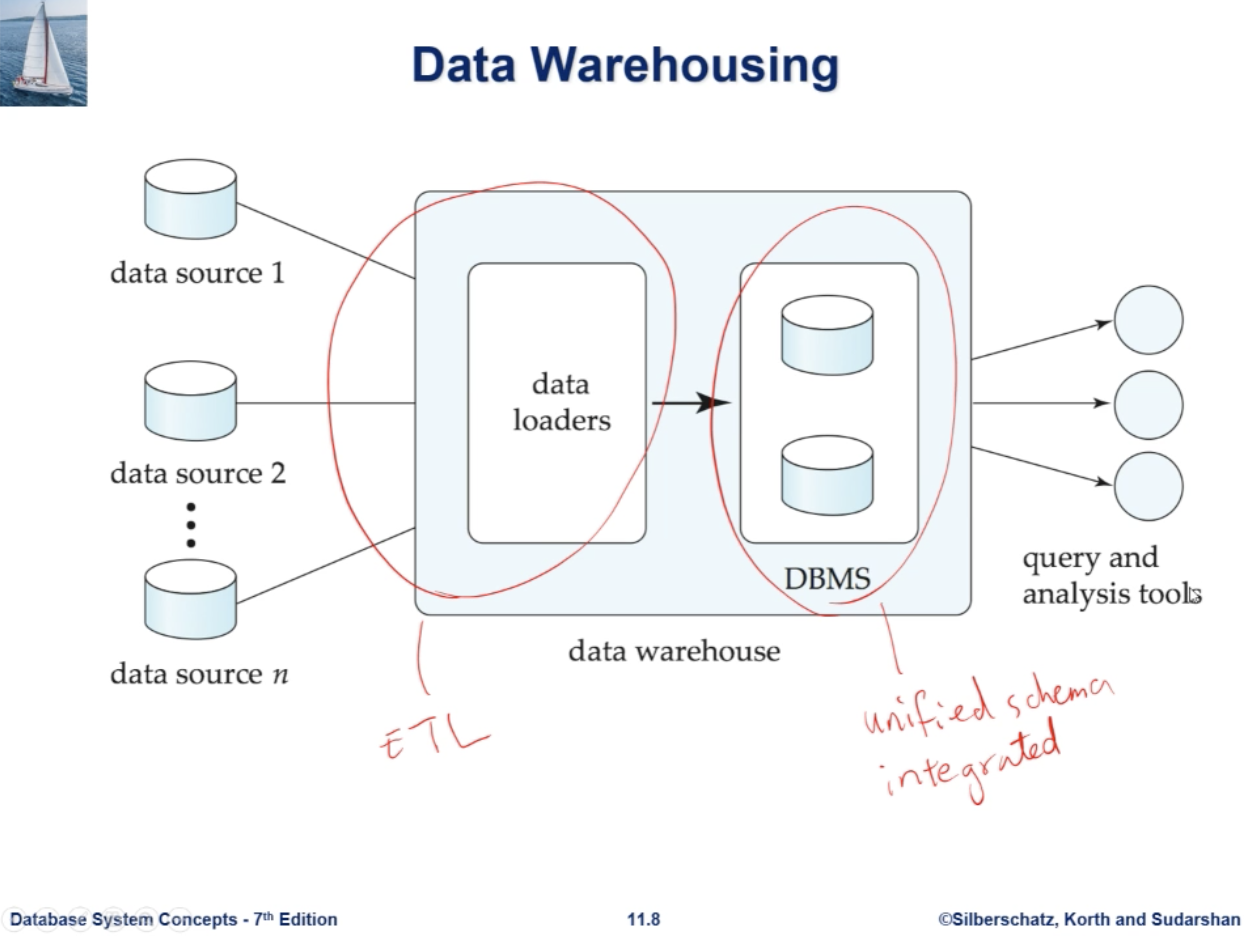
ETL : Extract-Transform-load
Design Issue
When and how to gather data
- Source driven architecture : data source가 warehouse에 새 정보를 전달 (연속적으로, 주기적으로)
- Destination driven architecture : warehouse가 주기적으로 data source에 새 정보를 요청
- Synchronous VS asynchronous replication
- warehouse를 data source와 정확히 동기화하면 너무 비용이 크다
- 약간 지난 데이터를 warehouse에 두는 것은 괜찮음
- update는 OLTP(online transaction processing system)에서 주기적으로 다운받음
What schema to use
- schema integration
Data transformation and data cleansing
- 주소에 적힌 틀린 값 수정하기 (오타, 우편번호 에러)
- Merge address lists from different sources and Purge duplicates
- +) purge : 일정 기간까지 유지하고 이후에 삭제
How to propagate updates
- View of schema from data source를 유지하기 위해서 존재하는 warehouse schema
What data to summarize
• Raw data may be too large to store on-line
• Aggregate values (totals/subtotals) often suffice
• Queries on raw data can often be transformed by query optimizer to use aggregate values
Multidimensional Data
Data in warehouse = Fact table + Dimension tables
Fact table : 사실의 정보만 담음. 굉장히 큼
E.g, sales(item_id, store_id, customer_id, date, number, price)
Dimension table : 보고싶은 column만 추출. 상대적으로 작음
이들을 쿼리문으로 어떻게 사용하냐면…
fact table을 dimension table에 join해서
dimension table attributes에 group by를 써서
fact table의 measure attribute에 집계함수 사용해서
Fact table의 속성의 view 관점으로는 …
- Measure attributes
- ex) sales와 price의 관계 알아보기
- dimension attributes
- measure attribute 표에서 그 행에 여러 컬럼들도 함께 출력
- sales와 color, size 관계도 관측하는 등
- foreign key를 dimension table의 primary key로 두기도 함
-

Warehouse Schemas
star schema
== resultant schema

snowflake schema

dimension table의 dimension table… -> multiple levels of dimension tables
fact tables도 여러 개 가질 수 있음
Data lakes
repositories which allow data to be stored in multiple formats,
without schema integration .
Less upfront effort, but more effort during querying
Database Support for Data Warehouse
warehouse의 data는 append only, not updated
-> update를 하면 concurrency control로 인한 overhead 발생
-> column-oriented storage 식으로 append 진행
E.g., a sequence of sales tuples is stored as follows
▪ Values of item_id attribute are stored as an array
▪ Values of store_id attribute are stored as an array,
▪ And so on
▪ Data warehouses often use parallel storage and query processing infrastructure
• Distributed file systems, Map-Reduce, Hive, …
'Web > DB & Cloud' 카테고리의 다른 글
| Data Mining - descriptive pattern (0) | 2021.12.10 |
|---|---|
| Data Mining - prediction mechanism (0) | 2021.12.10 |
| OLAP : Online Analytical Processing (0) | 2021.12.10 |
| Ranking & Windowing (0) | 2021.12.10 |
| Oracle Storage : Partitioning & Indexing (0) | 2021.12.09 |