OLAP is for multidimensional data
Data = measure attribute + dimension attributes
measure attribute
측정한 값, 집계 함수로 계산한 값들
dimension attributes
measure attribute를 이용하여 특정 관점을 정의
여기서 quantity는 measure attribute
앞의 3개는 dimension attributes

Cross Tabulation (= Pivot-table)
item_name과 color에 대해 sales 누적 계수 계산하기 total이 all 키워드가 있는 곳을 가져왔다고 할 수 있음 |
cross-tabe은 relation(컬럼 간 관계)를 표현할 수 있다 'all' 키워드로 쓰는데 null이 아니니 혼동하지 말자  |
select item_name, color, sum(number)
from sales
group by cube(item_name, color)“all” keyword
특정 column의 값은 무시하여 그 quantity를 합계해서 정리
또 그들끼리의 total도 구해주는 착한 것
dark skirt 합치면 2+5+1 = 8
Cross Tabulation With Hierarchy
hierarchy가 생기면 drill down 또는 roll up을 적용할 수 있음
아래 예시에서 category 먼저 고려하고 item_name을 고려함
이런 식으로 위계를 지정
sub total 이란 개념이 생김
점점 detail하게 가야하는 정보 순서로 위계 지정
높->낮 : drill down
낮->높 : roll up

Data Cube
cross-tab을 다차원으로 하면 cube
그럼 cube에게 cross-tab은 하나의 관점(view)가 된다
select item_name, color, clothes_size, sum(quantity)
from sales
group by cube(item_name, color, clothes_size)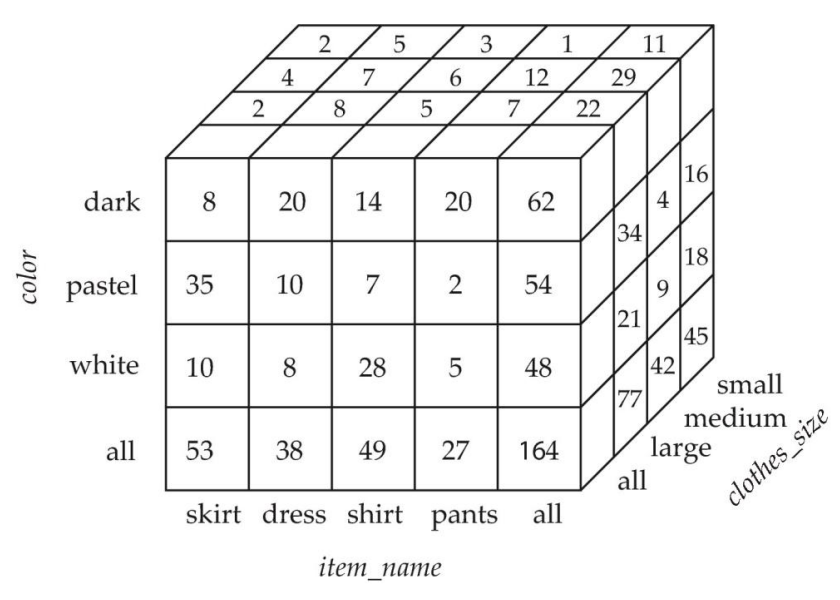
이를 통해 8개의 그룹(관계)가 생성된다
- (item_name, color, size)
- (item_name, color), (item_name, size)
- (color, size), (item_name)
- (color), (size)
- ( )
OLAP Opeartions
grouping()
all로 표현된 null 값에는 1을 반환
그 외의 경우 0을 반환
select item_name, color, size, sum(number),
grouping(item_name) as item_name_flag,
grouping(color) as color_flag,
grouping(size) as size_flag,
from sales
group by cube(item_name, color, size)
decode()
null 값을 원하는 값으로 바꿔줌
-- replace item_name in first query by
decode( grouping(item_name), 1, ‘all’, item_name)
Extended Aggregation - cube() 말고
Roll up
: 각 집합에 대해 합집합을 구성
hierarchy이 여러 층위를 합치는데 이용
(더 미세한 데이터로부터 더 단단한 세분화로 이동)
select item_name, color, size, sum(number)
from sales
group by rollup(item_name, color, size)이를 통해 4개의 그룹(관계)가 생성된다
- (item_name, color, size)
- (item_name, color), (item_name, size)
- ( )
아래 예시는 sales 테이블 속 값에 대해 category를 알려주는
itemcategory(itme_name, category)를 이용하여 item_name, category에 대해 요약하는 것
select category, item_name, sum(number)
from sales, itemcategory
where sales.item_name = itemcategory.item_name
group by rollup(category, item_name)
roll up을 하나의 쿼리 내에서 여러 개 쓸 수 있다.
각 roll up 결과 그룹을 곱셈하면 됨
select item_name, color, size, sum(number)
from sales
group by rollup(item_name), rollup(color, size){item_name, ()} X {(color, size), (color), ()}
- (item_name, color, size)
- (item_name, color),
- (item_name),
- (color, size),
- (color),
- ( )
Drill Down
roll up 의 반대
Slicing (dicing)
고정된 값에 대해 cross-tab 생성
- slice: 1개의 차원을 고른 뒤에 새로운 서브 큐브(sub cube) 만들기
- dice: 2개 이상의 차원를 골라 새로운 서브 큐브(sub cube)를 만들기


Pivoting
cross-tab 내의 차원을 변경할 때 호출됨
축을 돌려서 데이터를 표현

출처: https://loustler.io/data_eng/basic-analytical-operations-of-olap-part-2/
OLAP Implementation
MOLAP (multidimensional) - 초기 OLAP 버전
ROLAP (relational)
hybrid OLAP (HOLAP)
2^N의 GROUP BY의 조합은 굉장히 많은 용량과 시간이 소요
몇 개의 집계 함수는 미리 계산하여 다른 집계 함수에 이용할 수 있도록 해둠
sorting이나 roll up 시 굉장히 도움이 되는 방법
평균 구하기 처럼 더이상 분해할 수 없는 집계함수 제외
초기 OLAP 시스템은 온라인 응답을 제공하기 위해 가능한 모든 Aggregate를 미리 계산했습니다.
• 이를 위한 공간 및 시간 요구 사항은 매우 높을 수 있습니다.
2^n 그룹 조합 기준
• 일부 Aggregate는 사전 계산하고, 사전 계산된 Aggregate 중 하나에서 필요에 따라 다른 Aggregate를 계산하면 충분합니다.
(item_name, 색상, 크기)의 Aggregate에서 (item_name, color)의 Aggregate를 계산할 수 있습니다.
• 중앙값과 같은 일부 "분해할 수 없는"(non-decomposable) 집계에 대해
• 처음부터 계산하는 것보다 싸다
여러 Aggregate를 계산하는 데 사용할 수 있는 몇 가지 최적화
• (item_name, 색상, 크기)의 Aggregate에서 (item_name, color)의 Aggregate를 계산할 수 있습니다.
• 기본 데이터를 한 번 정렬하여 (item_name, color, size), (item_name) 및 (item_name)에 대한 집계를 계산할 수 있습니다.
'Web > DB & Cloud' 카테고리의 다른 글
| Data Mining - prediction mechanism (0) | 2021.12.10 |
|---|---|
| Data Warehouse (0) | 2021.12.10 |
| Ranking & Windowing (0) | 2021.12.10 |
| Oracle Storage : Partitioning & Indexing (0) | 2021.12.09 |
| MySQL 데이터 타입 (0) | 2021.05.12 |