Oracle에서
데이터베이스는 파일 속 정보로 구성되었으며
instace를 통해 접근 가능하다
instance는 shared memory area로,
data file과 상호작용하는 process들의 집합이다
Table Space
Oracle Table Spaces
- System table space : 항상 생성됨. data dictionary로, trigger로, stored procedures로..
- User table space : user data 저장
- Temporary table space : 정렬 같은 연산용 임시 데이터
Table space <- segment <- extent
table은 partition될 수도 있고, index를 가질 수 있음

Types of segment
- Data segments : for table data
- Index segments : for index
- Temporary segments : for sorting etc
- Rollback segments : for uncommitted transaction
Extent
각 extent는 contiguous(연속적인) blocks의 집합으로 구성됨
Oracle Storage parameter
블록이 꽉 찬 것으로 간주되는 공간 활용률(%)
instace를 저장하는 방법을 지정
데이터 접근하는데 걸리는 시간 및 공간을 효율적으로 사용할 수 있도록 함
CREATE TABLE divisions
(div_no NUMBER(2),
div_name VARCHAR2(14),
location VARCHAR2(13) )
STORAGE ( INITIAL 100K
NEXT 50K
MINEXTENTS 1 MAXEXTENTS 50
PCTINCREASE 5);- MINEXTENS 1 ) table에 1 extent 할당
- INITIAL 100K ) 첫 번째 extent 크기 = 100킬로바이트
- 테이블 데이터가 첫 번째 extent의 크기를 초과할 경우, 오라클은 두 번째 extent를 할당
- NEXT 50K 이므로 두 번째 extent의 크기는 50킬로바이트가 됨
- 이후 테이블 데이터가 처음 두 extent를 초과할 경우 Oracle은 세 번째 extent를 할당합니다.
- PCTINCREASE 5 ) percentage of increase rate of extent size
- 세 번째 extent의 계산된 크기는 두 번째 extent인 52.5 킬로바이트보다 5% 더 큽니다.
- 데이터 블록 크기가 2킬로바이트이면 오라클은 이 값을 52킬로바이트로 반올림합니다.
- 테이블 데이터가 계속 증가하면 Oracle은 이전보다 각각 5%씩 더 많은 extent를 할당합니다.
- MAXEXTENS 50 ) Oracle은 테이블에 최대 50개의 extent를 할당할 수 있습니다.
Partitioning
Oracle은 다양한 종류의 horizaontal partitioning을 지원함
장점
- Backup and recovery are easier and faster
- Loading operations in data warehouse이 덜 방해된다
-
필요한 partition의 하위 집합만 optimizer가 인식하므로 성능 상의 이점이 크다
Type of Partitioning
- Range Partitioning : 범위에 따라 분리
-
-- creates a table of four partitions, one for each quarter of sales. -- The columns sale_year, sale_month, and sale_day are the partitioning columns, -- while their values constitute the partitioning key of a specific row. -- The VALUES LESS THAN clause determines the partition bound: -- rows with partitioning key values that compare less than the ordered list of values -- specified by the clause are stored in the partition. -- Each partition is given a name (sales_q1, sales_q2, ...), and -- each partition is contained in a separate tablespace (tsa, tsb, ...). CREATE TABLE sales ( prod_id NUMBER(6) , cust_id NUMBER , time_id DATE , channel_id CHAR(1) , promo_id NUMBER(6) , quantity_sold NUMBER(3) ,amount_sold NUMBER(10,2) ) STORAGE (INITIAL 100K NEXT 50K) LOGGING PARTITION BY RANGE (time_id) ( PARTITION sales_q1_2006 VALUES LESS THAN (TO_DATE('01-APR-2006','dd-MON-yyyy')) TABLESPACE tsa STORAGE (INITIAL 20K NEXT 10K) , PARTITION sales_q2_2006 VALUES LESS THAN (TO_DATE('01-JUL-2006','dd-MON-yyyy')) TABLESPACE tsb , PARTITION sales_q3_2006 VALUES LESS THAN (TO_DATE('01-OCT-2006','dd-MON-yyyy')) TABLESPACE tsc , PARTITION sales_q4_2006 VALUES LESS THAN (TO_DATE('01-JAN-2007','dd-MON-yyyy')) TABLESPACE tsd ) ENABLE ROW MOVEMENT;
-
- Hash Partitioning : hash 함수 이용
-
-
-- The partitioning column is id, -- four partitions are created and assigned system generated names, -- and they are placed in four named tablespaces (gear1, gear2, ...) CREATE TABLE scubagear (id NUMBER, name VARCHAR2 (60)) PARTITION BY HASH (id) PARTITIONS 4 STORE IN (gear1, gear2, gear3, gear4); -
-- with "STORAGE" extent -- The initial extent size for each hash partition (segment) -- is also explicitly stated at the table level, -- and all partitions inherit this attribute. CREATE TABLE dept (deptno NUMBER, deptname VARCHAR(32)) STORAGE (INITIAL 10K) PARTITION BY HASH(deptno) (PARTITION p1 TABLESPACE ts1, PARTITION p2 TABLESPACE ts2, PARTITION p3 TABLESPACE ts1, PARTITION p4 TABLESPACE ts3);
-
- Composite Partitioning : table은 range partition을 한 뒤 그 결과에 대해 hash partition 적용
-
-- creates a range-hash partitioned table -- Four range partitions are created, each containing eight subpartitions. -- Because the subpartitions are not named, system generated names are assigned, -- but the STORE IN clause distributes them across the 4 specified tablespaces (ts1, ...,ts4). CREATE TABLE sales ( prod_id NUMBER(6) , cust_id NUMBER , time_id DATE , channel_id CHAR(1) , promo_id NUMBER(6) , quantity_sold NUMBER(3) , amount_sold NUMBER(10,2) ) PARTITION BY RANGE (time_id) SUBPARTITION BY HASH (cust_id) SUBPARTITIONS 8 STORE IN (ts1, ts2, ts3, ts4) ( PARTITION sales_q1_2006 VALUES LESS THAN (TO_DATE('01-APR-2006','dd-MON-yyyy')) , PARTITION sales_q2_2006 VALUES LESS THAN (TO_DATE('01-JUL-2006','dd-MON-yyyy')) , PARTITION sales_q3_2006 VALUES LESS THAN (TO_DATE('01-OCT-2006','dd-MON-yyyy')) , PARTITION sales_q4_2006 VALUES LESS THAN (TO_DATE('01-JAN-2007','dd-MON-yyyy')) );
-
- List Partitioning : 특정 파티션과 관련된 값이 목록에 명시되어 있음
-
-- creates table "sales_by_region" and partitions it using the list method -- The first two PARTITION clauses specify physical attributes, -- which override the table-level defaults. -- The remaining PARTITION clauses do not specify attributes -- and those partitions inherit their physical attributes from table-level defaults. -- A default partition is also specified. CREATE TABLE sales_by_region (item# INTEGER, qty INTEGER, store_name VARCHAR(30), state_code VARCHAR(2), sale_date DATE) STORAGE(INITIAL 10K NEXT 20K) TABLESPACE tbs5 PARTITION BY LIST (state_code) ( PARTITION region_east VALUES ('MA','NY','CT','NH','ME','MD','VA','PA','NJ') STORAGE (INITIAL 8M) TABLESPACE tbs8, PARTITION region_west VALUES ('CA','AZ','NM','OR','WA','UT','NV','CO') NOLOGGING, PARTITION region_south VALUES ('TX','KY','TN','LA','MS','AR','AL','GA'), PARTITION region_central VALUES ('OH','ND','SD','MO','IL','MI','IA'), PARTITION region_null VALUES (NULL), PARTITION region_unknown VALUES (DEFAULT) );
-
Index 추출하기
한 컬럼에 대해서 그 행의 index(id)만 모아놓은 테이블 생성
이는 방대한 데이터 속에서 값을 찾아야 할 때 유용
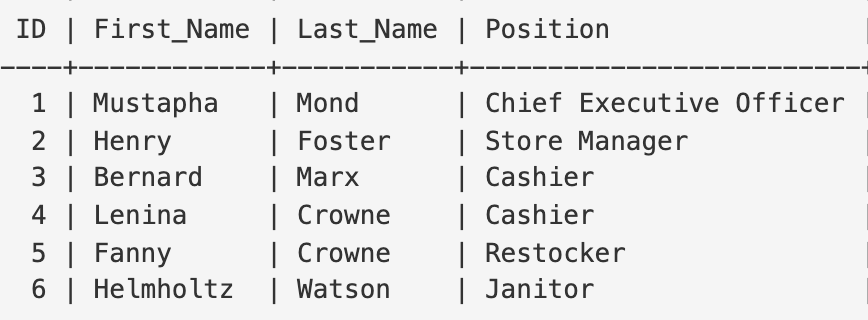
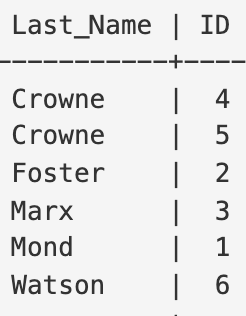

CREATE TABLE `Employees` (
`ID` TINYINT(3) UNSIGNED NOT NULL,
`First_Name` VARCHAR(25) NOT NULL,
`Last_Name` VARCHAR(25) NOT NULL,
`Position` VARCHAR(25) NOT NULL,
`Home_Address` VARCHAR(50) NOT NULL,
`Home_Phone` VARCHAR(12) NOT NULL,
`Employee_Code` VARCHAR(25) NOT NULL,
PRIMARY KEY (`ID`),
UNIQUE KEY (`Employee_Code`) -- 중복 불가
) ENGINE=Aria;ALTER TABLE Employees ADD PRIMARY KEY(ID);ALTER TABLE Employees ADD UNIQUE `EmpCode`(`Employee_Code`);
-- or
CREATE UNIQUE INDEX HomePhone ON Employees(Home_Phone);CREATE INDEX xi ON xx5 (x);
-- Query OK, 0 rows affected (0.03 sec)
CREATE INDEX xi ON xx5 (x);
-- ERROR 1061 (42000): Duplicate key name 'xi'
CREATE OR REPLACE INDEX xi ON xx5 (x);
-- Query OK, 0 rows affected (0.03 sec)
CREATE INDEX IF NOT EXISTS xi ON xx5 (x);
-- Query OK, 0 rows affected, 1 warning (0.00 sec)
SHOW WARNINGS;
-- +-------+------+-------------------------+
-- | Level | Code | Message |
-- +-------+------+-------------------------+
-- | Note | 1061 | Duplicate key name 'xi' |
-- +-------+------+-------------------------+B-tree index
insert, update, delete 모두 log(n)의 성능
형식 : <col1> <col2> <col3> ... <row-id>
Bitmap index
bitmap으로 index 항을 명시
형식 : <col1><startrow-id><endrow-id><compressedbitmap>
bitmap은 테이블의 시작 row과 끝 row-id 사이에 가능한 모든 행의 공간을 나타냄
bitmap의 각 bit는 블록의 한 행을 나타냄
비트맵에서 부울 연산을 통해 쿼리의 동일한 테이블에 있는 여러 조건을 처리할 수 있습니다.
ex) (col1=1 or col1=2) and col2 > 5 and col3 <> 10
Function-Base index
하나 또는 그 이상의 columns를 포함한 표현을 통해 index 생성
ex-expression) col1 + col2 * 5
ex-usage) upper(name)으로 생성된 index는 무조건 대문자만 가짐
Join index
인덱스의 row-id에서 참조하는 테이블에 key column이 없는 인덱스
ex)
- 'product' dimension table 속 'product name' column
- 이러한 key column을 가진 fact table에 대한 bitmap join index는 product의 특정 이름과 일치하는 fact table rows를 회수하는데 사용합니다. 이는 name이 fact table에 저장되어 있지 않더라도 동작합니다.
Domain Index
Oracle에 친숙한 data type이 아닐 때, (text, spatial data, images)
Index designer는 index의 생성, 유지관리, 검색 시 Oracle server의 protocol을 준수해야 함
- Domain index는 지원하는 연산자와 함께 data dictionary에 등록되어야 함
- Domain index에 대한 cost function도 등록할 수 있음
- Oracle optimizer는 Domain index를 액세스 경로로 간주
Domain index를 사용할 수 있는 쿼리 예제
SELECT * FROM employee
WHERE contains(resume, 'LINUX')
-- resume : text column in employees table
+)
Table scan Method
- Full table scan : Query processor scans entire table
- Index scan : Processor가 query의 조건에서 start, stop key를 만들어서 index의 관련 부분을 검색하는데 사용
- Index fast full scan : Processor가 full table scan과 유사하만 방식으로 extent를 스캔
- Index Join : query에 필요한 모든 column을 포함하는 index가 없는 경우, 필요한 column을 포함하는 index를 함께 join
- Cluster and Hash cluster access : Processor가 cluster key를 사용하여 데이터에 접근
Join
inner joins, outer joins, semijoins, antijoins
hash join, sort-merge join, or nested loop join ...
'Web > DB & Cloud' 카테고리의 다른 글
| OLAP : Online Analytical Processing (0) | 2021.12.10 |
|---|---|
| Ranking & Windowing (0) | 2021.12.10 |
| MySQL 데이터 타입 (0) | 2021.05.12 |
| DML - INSERT, UPDATE, DELETE, CREATE, DROP (0) | 2021.05.12 |
| DML - SELECT + (where, order, group) (0) | 2021.05.10 |