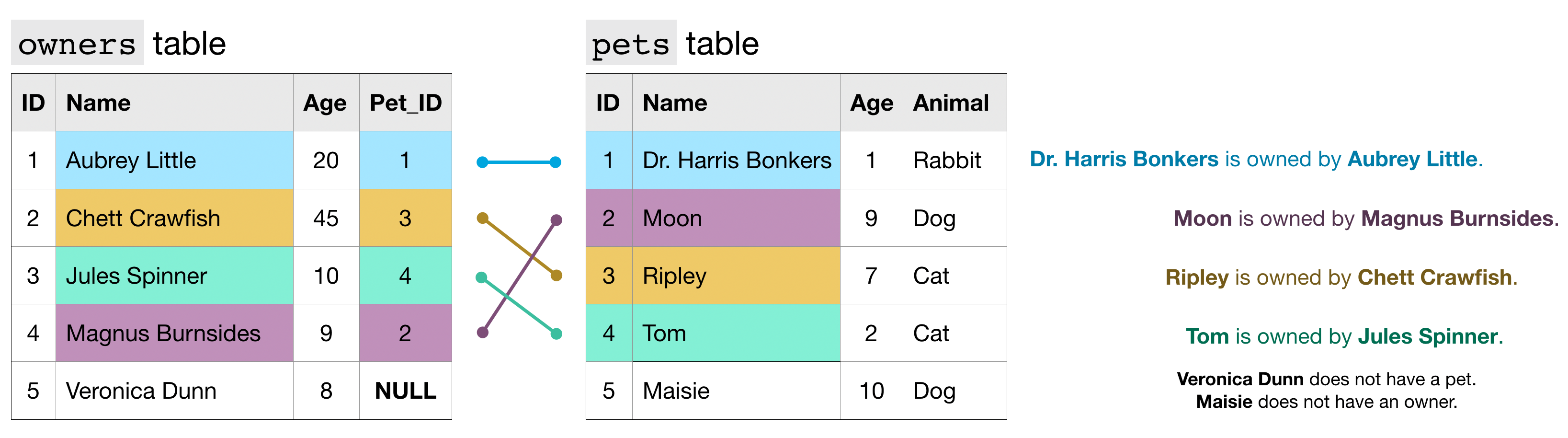
INNER JOIN

Inner JOIN을 하니, 'oweners'의 Veronica Dunn씨와 'pets'의 Maisie가 누락되었습니다.
이럴 때 다른 JOIN을 써야 합니다.
LEFT JOIN & (RIGHT JOIN)

LEFT JOIN: 왼쪽에 적은 table의 모든 row를 포함하여 join하기
맨 위 사진의 INNER JOIN으로 명시된 부분을 LEFT JOIN으로 바꾸기만 하면 됩니다.
RIGHT JOIN: 오른쪽에 적은 table의 모든 row를 포함하여 join하기
FULL JOIN
두 TABLE의 모든 rows를 반환.
일반적으로, 모든 row가 서로 매칭되는 경우는 극히 드물기에
그런 경우에 대해서 'NULL' entry가 생성되어 missing value를 채워줍니다.
UNION
JOIN은 수평적으로 TABLE를 묶었지만, UNION은 수직적으로, columns를 이어붙입니다.(concatenate)
주의할 점은, column 속 data의 type이 일치해야한다는 점입니다. column 이름을 달라도 괜찮지만요

UNION ALL : 겹치는 값들도 포함
숫자 9는 owner table에서도, pet table에서도 나타나기에 합쳐진 결과에는 두 번 나타납니다.
이를 방지하고 싶다면,
UNION DISTINCT : 겹치는 값 제외하여 이어붙이기
Ex. Hacker News dataset
from google.cloud import bigquery
# Create a "Client" object
client = bigquery.Client()
# Construct a reference to the "hacker_news" dataset
dataset_ref = client.dataset("hacker_news", project="bigquery-public-data")
# API request - fetch the dataset
dataset = client.get_dataset(dataset_ref)
# Construct a reference to the "comments" table
table_ref = dataset_ref.table("comments")
# API request - fetch the table
table = client.get_table(table_ref)
# Preview the first five lines of the table
client.list_rows(table, max_results=5).to_dataframe()
# Construct a reference to the "stories" table
table_ref = dataset_ref.table("stories")
# API request - fetch the table
table = client.get_table(table_ref)
# Preview the first five lines of the table
client.list_rows(table, max_results=5).to_dataframe()
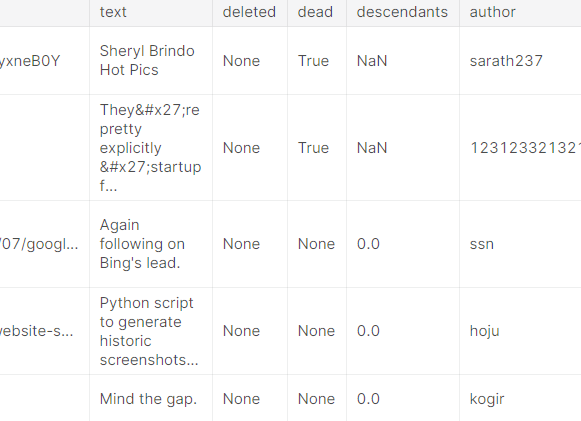
1. LEFT JOIN -> comment를 받지 못한 stories 추출
common table expression (CTE). 사용
# Query to select all stories posted on January 1, 2012, with number of comments
join_query = """
WITH c AS
(
SELECT parent, COUNT(*) as num_comments
FROM `bigquery-public-data.hacker_news.comments`
GROUP BY parent
)
SELECT s.id as story_id, s.by, s.title, c.num_comments
FROM `bigquery-public-data.hacker_news.stories` AS s
LEFT JOIN c
ON s.id = c.parent
WHERE EXTRACT(DATE FROM s.time_ts) = '2012-01-01'
ORDER BY c.num_comments DESC
"""
# Run the query, and return a pandas DataFrame
join_result = client.query(join_query).result().to_dataframe()
join_result.head()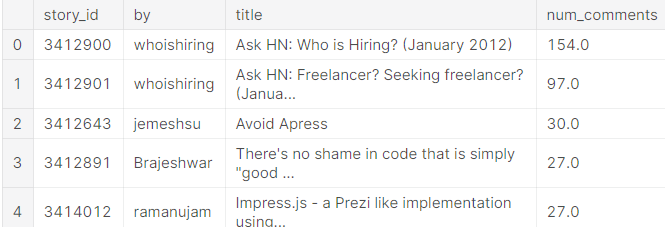
'num_comments' column을 기준으로 정렬되었기에, 댓글 없는 story는 DataFrame의 마지막 부분에 나옵니다.
(NaN == Not a Number)
# None of these stories received any comments
join_result.tail()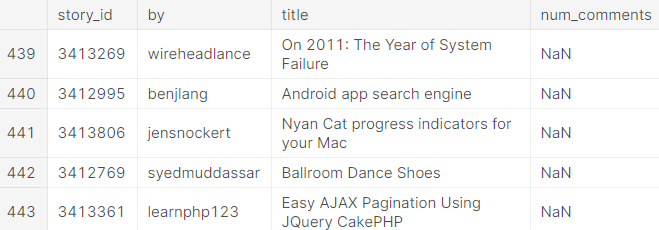
2. UNION DISTINCT -> 2014.01.01에 comments 또는 story를 쓴 모든 username 찾기
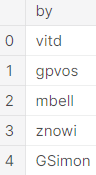
# Query to select all users who posted stories or comments on January 1, 2014
union_query = """
SELECT c.by
FROM `bigquery-public-data.hacker_news.comments` AS c
WHERE EXTRACT(DATE FROM c.time_ts) = '2014-01-01'
UNION DISTINCT
SELECT s.by
FROM `bigquery-public-data.hacker_news.stories` AS s
WHERE EXTRACT(DATE FROM s.time_ts) = '2014-01-01'
"""
# Run the query, and return a pandas DataFrame
union_result = client.query(union_query).result().to_dataframe()
# Number of users who posted stories or comments on January 1, 2014
len(union_result) #2282
union_result.head()
혹시, 그 사용자의 수를 알고 싶다면, 그 결과로 나온 dataframe의 길이만 알면 됩니다.
Exercise
Stack Overflow dataset에 대한 질문에 답하기 위해 JOIN의 여러 종류를 써보려합니다.
Setup
from google.cloud import bigquery
# Create a "Client" object
client = bigquery.Client()
# Construct a reference to the "stackoverflow" dataset
dataset_ref = client.dataset("stackoverflow", project="bigquery-public-data")
# API request - fetch the dataset
dataset = client.get_dataset(dataset_ref)
# Construct a reference to the "posts_questions" table
table_ref = dataset_ref.table("posts_questions")
# API request - fetch the table
table = client.get_table(table_ref)
# Preview the first five lines of the table
client.list_rows(table, max_results=5).to_dataframe()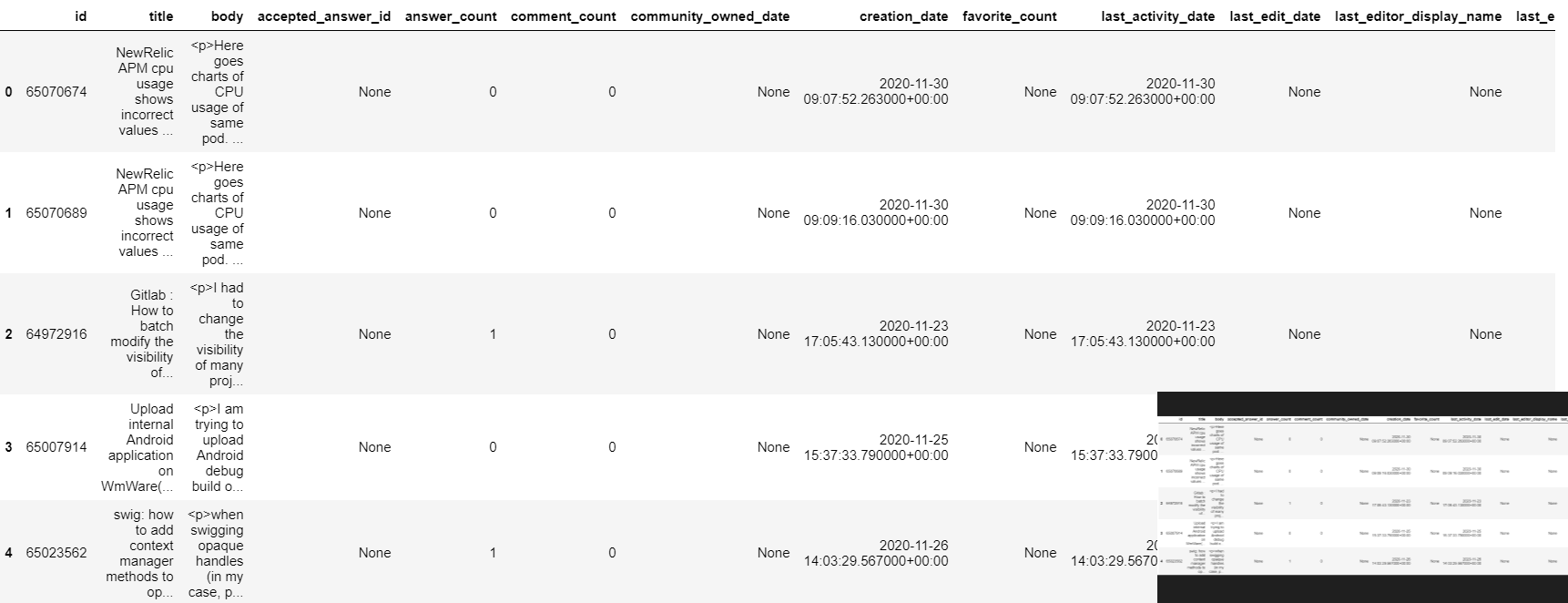
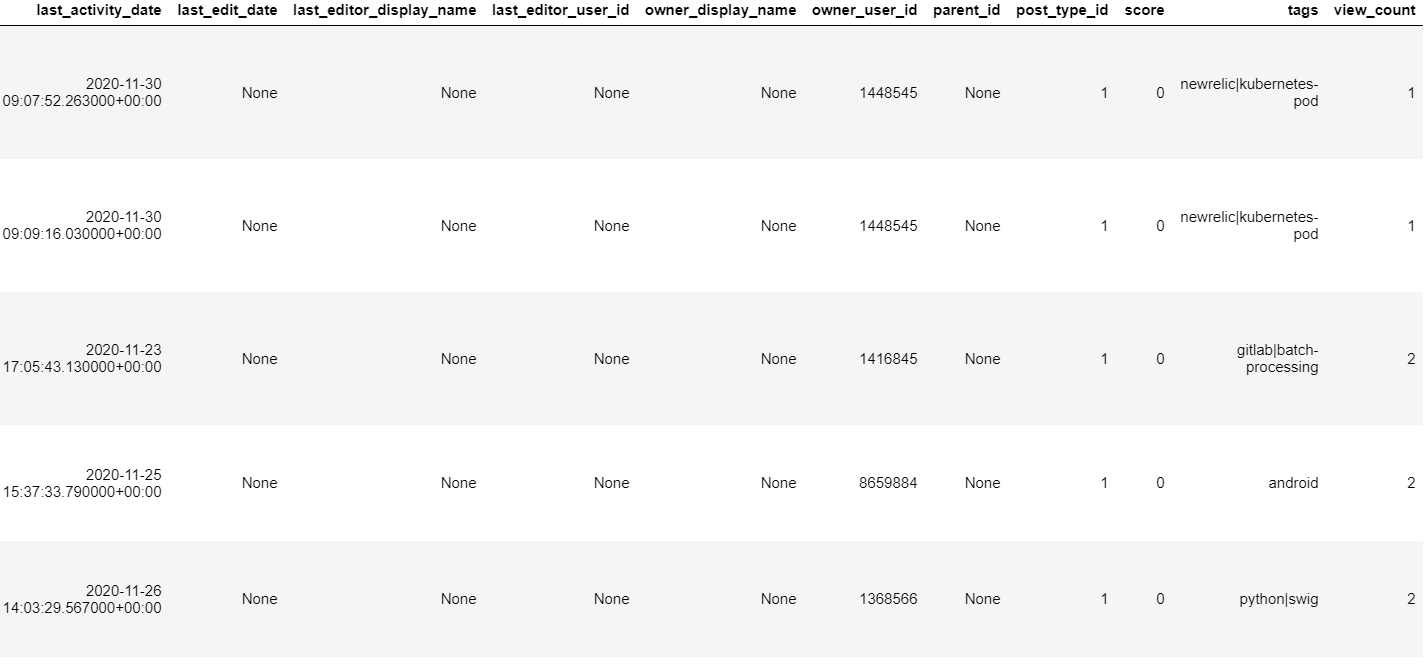
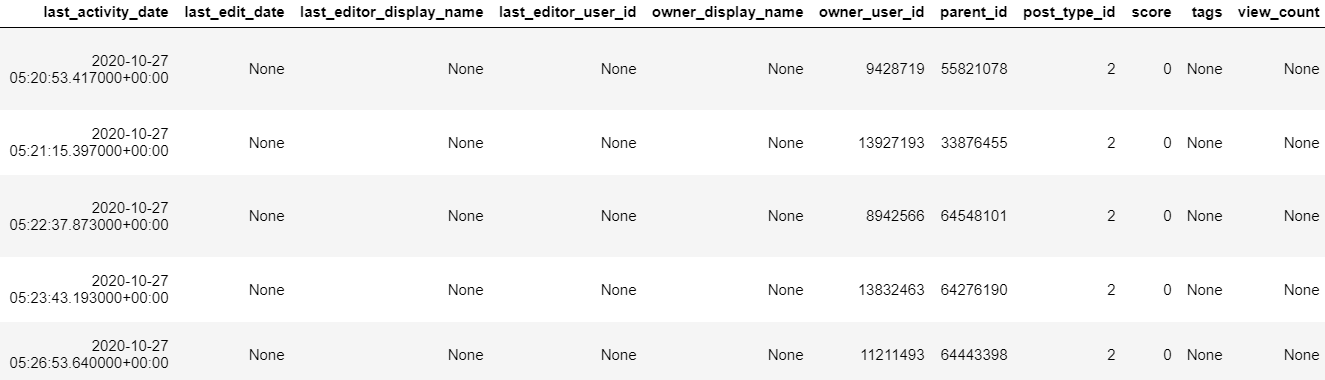
# Construct a reference to the "posts_answers" table
table_ref = dataset_ref.table("posts_answers")
# API request - fetch the table
table = client.get_table(table_ref)
# Preview the first five lines of the table
client.list_rows(table, max_results=5).to_dataframe()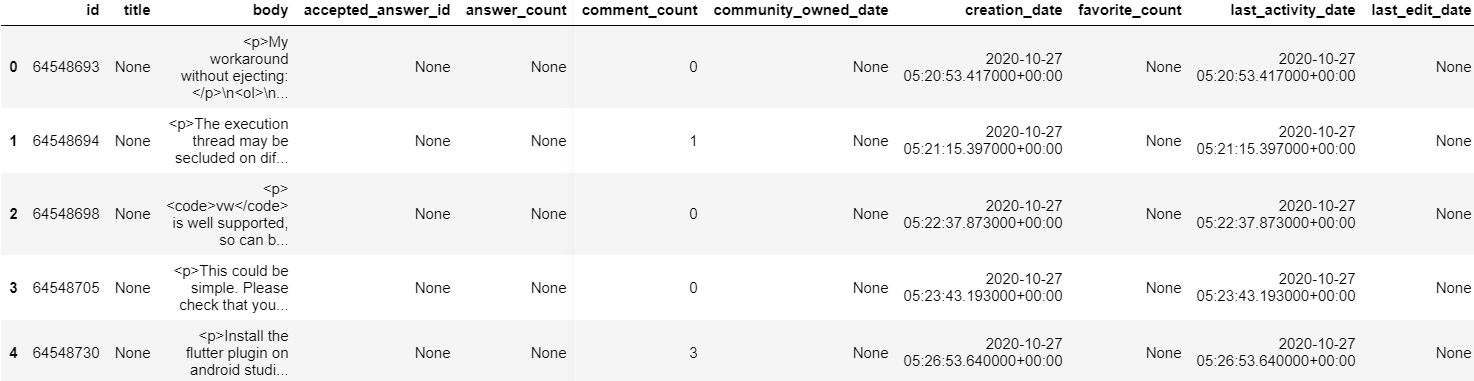
Q1) 질문에 대한 답변을 받기까지 얼마나 걸릴까?
일단 2018년 1월에 나온 질문에 초점을 두고 query문을 작성하려 합니다.
- q_id column : 질문의 ID
- time_to_answer : 답변받기까지 걸린 시간(초단위)
SELECT q.id AS q_id,
MIN(TIMESTAMP_DIFF(a.creation_date, q.creation_date, SECOND)) as time_to_answer
FROM `bigquery-public-data.stackoverflow.posts_questions` AS q
INNER JOIN `bigquery-public-data.stackoverflow.posts_answers` AS a
ON q.id = a.parent_id
WHERE q.creation_date >= '2018-01-01' and q.creation_date < '2018-02-01'
GROUP BY q_id
ORDER BY time_to_answerfirst_query = """
the query up over cold block
"""
first_result = client.query(first_query).result().to_dataframe()
print("Percentage of answered questions: %s%%" % \
(sum(first_result["time_to_answer"].notnull()) / len(first_result) * 100))
print("Number of questions:", len(first_result))
first_result.head()
# Percentage of answered questions: 100.0%
# Number of questions: 134577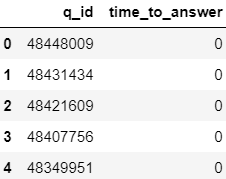
결과치를 보니 이상한 점이 한 두개가 아니네요.
- 2018년 1월에는 모든 질문에 (100%) 답변이 달렸다고 하지만, 실상은 80%이하의 질문만이 답변을 받습니다.
- 총 질문의 수도 너무 적습니다. (134577) 척어도 150000개의 질문이 table에 있을 거라 예상했는데 말이죠.
이러한 관찰을 토대로 어떤 종류의 JOIN을 선택해야 문제를 해결할 수 있는지 고민해솝니다.
결과에 답변이 달리지 않은 질문도 포함되게 만드려면 어떻게 해야할까요?
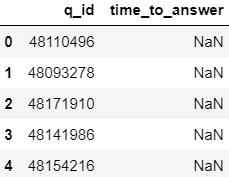
INNER JOIN이 아닌 LEFT JOIN을 사용해야합니다.
posts_questions table의 모든 row는 post_answer table과 상관없이 모두 필요해서
>>>Percentage of answered questions: 82.89006873783538%
>>>Number of questions: 162356
Q2) 가입한 사용자는 실제적으로 활동하기(질문/답변)까지 얼마나 걸릴까?
2019년 1월에 위 질문에 맞추어,
아래 column을 가진 table을 생성하는 query문을 작성하려 합니다.
- owner_user_id : 사용자의 ID
- q_creation_date : 사용자가 처음으로 질문을 올린 시점
- a_creation_date : 사용자가 처음으로 답변을 달아준 시점
주의할 점이 있습니다.
질문을 올린 사용자가 아직 답변을 올리기 전인지 확인해봐야합니다.
그리고 답변을 단 사용자 중 단 한 번도 질문을 올리지 않은 사용자인지도 말이죠.
SELECT q.owner_user_id AS owner_user_id,
MIN(q.creation_date) AS q_creation_date,
MIN(a.creation_date) AS a_creation_date
FROM `bigquery-public-data.stackoverflow.posts_questions` AS q
FULL JOIN `bigquery-public-data.stackoverflow.posts_answers` AS a
ON q.owner_user_id = a.owner_user_id
WHERE q.creation_date >= '2019-01-01' AND q.creation_date < '2019-02-01'
AND a.creation_date >= '2019-01-01' AND a.creation_date < '2019-02-01'
GROUP BY owner_user_id
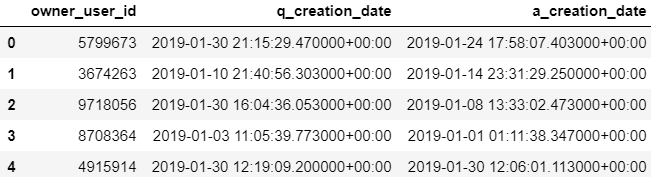
Q3) 가입한 사용자는 실제적으로 활동하기(질문/답변)까지 얼마나 걸릴까?
예시 설명) 서로 다른 JOIN 종류를 함께 써서 3개의 table을 하나로 만드는 query문을 작성한 예
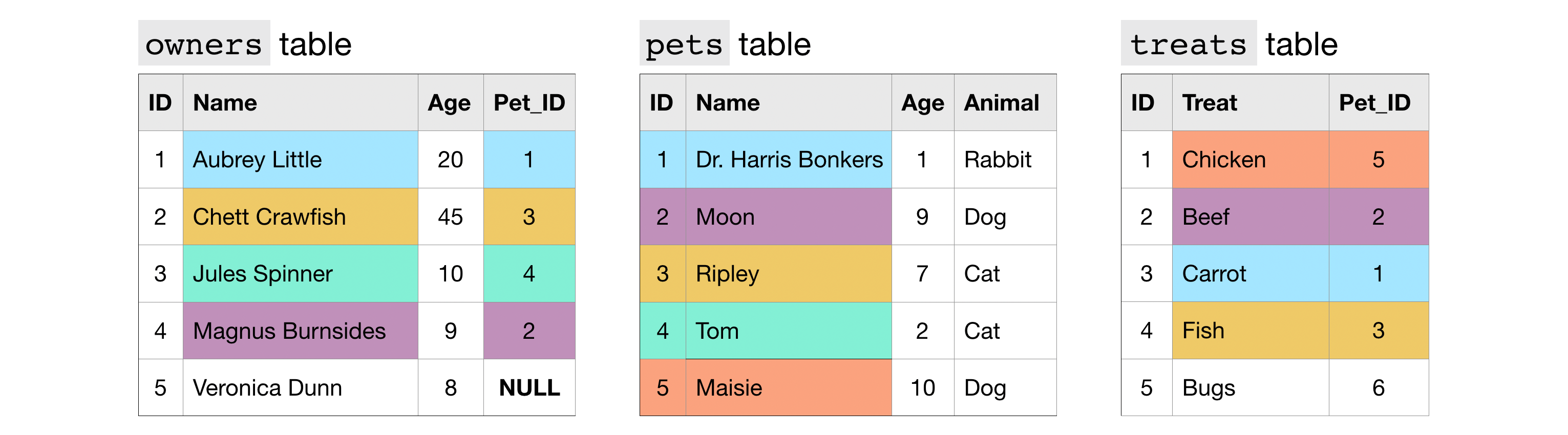

위의 설명을 바탕으로. 2019년 1월에 가입한 사용자들을 좀 더 조사해보려합니다.
그들은 언제 처음으로 질문, 답변을 올렸을까요?
아래 column을 가진 table을 생성하는 query문을 작성하려 합니다.
- id : 2019년 1월에 계정을 생성한 모든 사용자의 ID
- q_creation_date : 사용자가 처음으로 질문을 올린 시점, 만약 사용자가 단 한 번도 올리지 않았다면 null
- a_creation_date : 사용자가 처음으로 답변을 달아준 시점, 만약 사용자가 단 한 번도 올리지 않았다면 null
주의할 점은, 2019년 1월 이후의 해당 사용자의 사용 기록은 계속 추적해야합니다. 결과에 포함시켜야 합니다.
또한 2019년 1월에 가입한 사용자 중 질문도 올리지 않고 답변도 달아보지 않더라도 꼭 포함시켜야 합니다.
'posts_questions' table과 'posts_answer' table 모두 필요합니다.
StackOverflow dataset의 'users' table도 필요하죠. 이곳의 'id' column과 'creation_date' column을 사용해야합니다.
creation_date는 처음으로 가입한 시기를 DATETIME format으로 저장하고 있습니다.
SELECT u.id AS id,
MIN(q.creation_date) AS q_creation_date,
MIN(a.creation_date) AS a_creation_date
FROM `bigquery-public-data.stackoverflow.users` AS u
LEFT JOIN `bigquery-public-data.stackoverflow.posts_answers` AS a
ON u.id = a.owner_user_id
LEFT JOIN `bigquery-public-data.stackoverflow.posts_questions` AS q
ON q.owner_user_id = u.id
WHERE u.creation_date >= '2019-01-01' and u.creation_date < '2019-02-01'
GROUP BY id
Q4) 2019년 1월 1일에 포스팅을 올린 사용자의 수?
-아래 column을 가진 table을 생성하는 query문을 작성하려 합니다.
- owner_user_id : 2019년 1월에 적어도 하나의 질문 또는 답변을 올린 모든 사용자의 ID.
(각 사용자의 ID는 단 한 번씩만 출력되어야 합니다.)
날짜를 정확히 뽑아내는 함수 EXTRACT( DATE FROM ~~) 잊지마시고!
SELECT a.owner_user_id
FROM `bigquery-public-data.stackoverflow.posts_answers` AS a
WHERE EXTRACT(DATE FROM a.creation_date) = '2019-01-01'
UNION DISTINCT
SELECT q.owner_user_id
FROM `bigquery-public-data.stackoverflow.posts_questions` AS q
WHERE EXTRACT(DATE FROM q.creation_date) = '2019-01-01''Machine Learning > [Kaggle Course] SQL (Intro + Advanced)' 카테고리의 다른 글
| Nested and Repeated Data (0) | 2021.01.15 |
|---|---|
| How to Define Analytic/window Functions (0) | 2021.01.15 |
| JOIN (0) | 2020.12.09 |
| AS & WITH (0) | 2020.12.07 |
| ORDER BY (0) | 2020.12.05 |