|
|
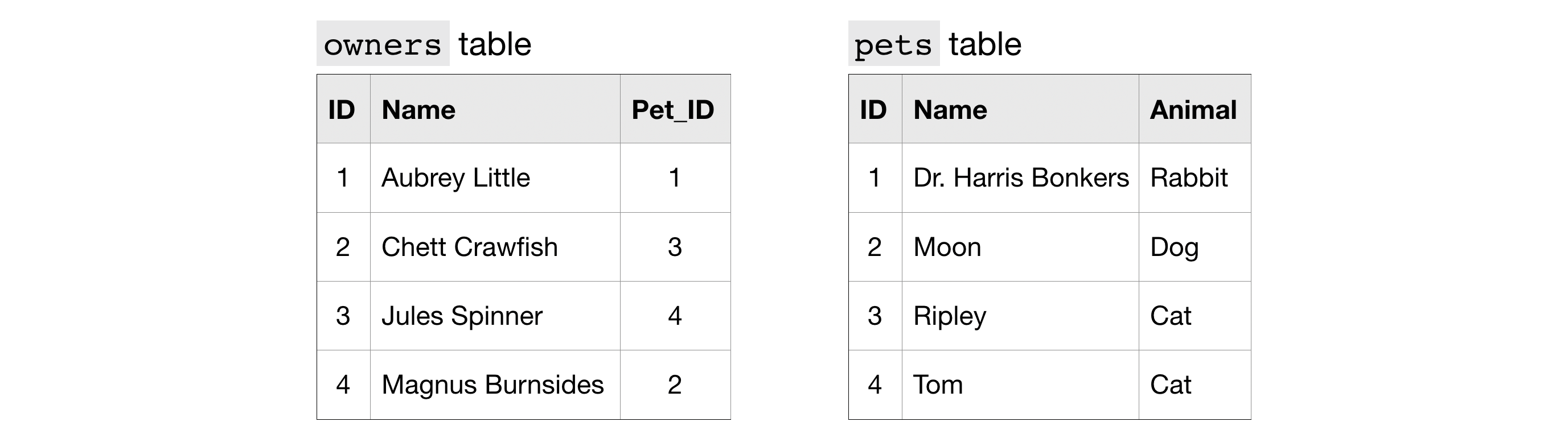
'owner' table의 pet_id와 'pet' table의 id는 같은 동물을 가리키므로 이를 이용해 JOIN
이를 통해 해당 동물의 이름을 알면 그 주인의 이름을, 또는 주인의 이름을 알면 그 동물의 이름과 종을 알 수 있음.

JOIN ... ON

위의 query에서, ON 명령문은 각 table에서 어느 column을 다른 여러 table에 결합시킬지 결정합니다.
ID column은 두 table에 있으므로, 사용할 column을 명확히 해야합니다.
'pets' table 의 'ID' column -> 'p.ID' column
'owner' table 의 'Pet_ID' column -> 'o.Pet_ID' column
보통 table을 join 시 각 table에서 어느 column끼리 묶을 지 지정하는 것이 좋습니다.
그렇게 하면 query를 읽기 위해 뒤로 돌아갈 때마다 schema를 끌어올릴 필요가 없어집니다.
지금 사용하는 join의 종류를 "INNER JOIN"이라고 합니다. 다른 종류는 나중에 배워봅시다.
즉 row를 결합하는 데 사용하는 column의 값은 join한 두 table에 모두 표시되는 경우에만 최종 출력 테이블에 그 row가 배치됩니다. 예로, Tom의 ID인 4라는 값이 'pet' table에 없으면 이 query에서 3줄만 반환됩니다.
EX. How many files are covered by each type of software license?
Github의 repository ( or repo)는 특정 project와 연관된 files의 집합(collection)입니다.
대부분의 repo는 특정 법적 저작권 (specific legal license)을 준수하며 공유되어집니다.
이번에는 각 license 별로 얼마나 많은 파일들이 released 되었는지 봅시다.
database에서 2 tables를 가져올 겁니다.
하나는 'licenses' table입니다.
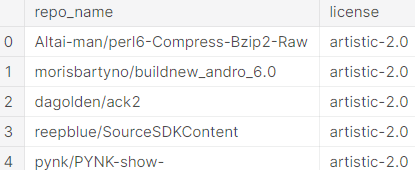
이는 각 GitHub repo의 이름 ('repo_name' column)을 제공하며 그것의 license 또한 알려줍니다.
from google.cloud import bigquery
# Create a "Client" object
client = bigquery.Client()
# Construct a reference to the "github_repos" dataset
dataset_ref = client.dataset("github_repos", project="bigquery-public-data")
# API request - fetch the dataset
dataset = client.get_dataset(dataset_ref)
# Construct a reference to the "licenses" table
licenses_ref = dataset_ref.table("licenses")
# API request - fetch the table
licenses_table = client.get_table(licenses_ref)
# Preview the first five lines of the "licenses" table
client.list_rows(licenses_table, max_results=5).to_dataframe()
다른 하나는 'sample_files' table입니다.
이는 서로 다른 정보 중에서도 그 파일이 속해있는 GitHub repo ('repo_name' column)를 알려줍니다.
# Construct a reference to the "sample_files" table
files_ref = dataset_ref.table("sample_files")
# API request - fetch the table
files_table = client.get_table(files_ref)
# Preview the first five lines of the "sample_files" table
client.list_rows(files_table, max_results=5).to_dataframe()
질문으로 돌아와, 각 license마다 얼마나 많은 파일들이 released 되었는지 query를 작성합시다.
# Query to determine the number of files per license, sorted by number of files
query = """
SELECT L.license, COUNT(1) AS number_of_files
FROM `bigquery-public-data.github_repos.sample_files` AS sf
INNER JOIN `bigquery-public-data.github_repos.licenses` AS L
ON sf.repo_name = L.repo_name
GROUP BY L.license
ORDER BY number_of_files DESC
"""
# Set up the query (cancel the query if it would use too much of
# your quota, with the limit set to 10 GB)
safe_config = bigquery.QueryJobConfig(maximum_bytes_billed=10**10)
query_job = client.query(query, job_config=safe_config)
# API request - run the query, and convert the results to a pandas DataFrame
file_count_by_license = query_job.to_dataframe()

파란색(JOIN ... ON) :
data의 출처와 table을 어떻게 join할 지에 대해 명시
ON으로 값이 서로 일치하는 'repo_name' column 기준으로 결합.
노란색(SELECT and GROUP BY) :
GROUP BY로 각 license별로 서로 다른 그룹으로 분리.
이후, COUNT로 각 license별로 일치하는 'sample_files' table 속 가로 줄의 수를 세어 봄.
(row의 수를 세고 싶을 땐 COUNT(1) 명심하기!)
보라색(ORDER BY) :
파일을 많이 가진 license부터 내림차순(DESC)으로 정렬
Exercise
Stack Overflow에 수많은 기술 관련 질문과 답변이 있습니다. SQL에 대해서도 있어요.
공식적으로 이용가능한 data ('stackoverflow' dataset)이니 어떻게 다뤄보면 좋을지 생각해봅시다
Idea 1. 특정 기술에 관련 질문에 답변하여 그에 대한 전문성을 입증한 Stack Overflow 사용자를 식별하는 서비스를 고안해봅시다. 이를 통해 해당 전문가를 고용하여 심층적인 도움을 받을 수 있습니다.
from google.cloud import bigquery
# Create a "Client" object
client = bigquery.Client()
# Construct a reference to the "stackoverflow" dataset
dataset_ref = client.dataset("stackoverflow", project="bigquery-public-data")
# API request - fetch the dataset
dataset = client.get_dataset(dataset_ref)
1st Explore the data
JOIN을 사용하기 전에 어떤 tables가 있는지 확인해봅시다.
# Get a list of available tables
list_of_tables = []
for table in list(client.list_tables(dataset)):
#print(table.table_id)
list_of_tables.append(table.table_id)
''' way2
list_of_tables = [table.table_id for table in list(client.list_tables(dataset))]
'''
# Print your answer
print(list_of_tables)
-> 'posts_answers' table
-> 'posts_questions' table
2nd Review relevant tables
주어진 topic에 대한 질문에 답변을 한 사람이 누군지 보고 싶다면, 'posts_answers' table을 보세요.
# Construct a reference to the "posts_answers" table
answers_table_ref = dataset_ref.table("posts_answers")
# API request - fetch the table
answers_table = client.get_table(answers_table_ref)
# Preview the first five lines of the "posts_answers" table
client.list_rows(answers_table, max_results=5).to_dataframe()
data가 그리 깔끔해보이지 않지만, 'post_answers' table 속 'parent_id' column으로 원하는 users를 찾을 순 있습니다.
당신이 Stack Overflow 사이트에 익숙한 사람이라면 'parent_id가 각 post의 답하는 질문임을 알 수 있습니다.
자, 그럼 'posts_questions' table을 볼까요?
# Construct a reference to the "posts_questions" table
questions_table_ref = dataset_ref.table("posts_questions")
# API request - fetch the table
questions_table = client.get_table(questions_table_ref)
# Preview the first five lines of the "posts_questions" table
client.list_rows(questions_table, max_results=5).to_dataframe()
각 질문에 대한 특정 topic 또는 tech를 식별할 수 있는 column(field)가 보이나요?
그렇다면, 그 특정 topic의 질문들에 답변한 user의 ID는 어떻게 찾으실 건가요?
뒤쪽에 'tag' column에 각 질문에 대한 topic/tech 분류가 기입되어있습니다.
'posts_answers' table에는 각 답변에 대한 질문의 ID를 식별해주는 'parent_id' column이 있죠.
또한 답변자의 ID를 식별해주는 'owner_user_id' column도 있어요.
이를 통해 두 table을 join할 수 있습니다.
- 각 답변에 대한 'tags'를 지정/결정하세요.
- 원하는 tag의 답변의 'owner_user_id'를 선택하세요(select)
3rd Selecting the right questions
대부분의 data가 text 형식입니다. 이번엔 text 형식에 적용할 수 있는 기술을 보여드리려 합니다.
WHERE 절은 특정 text를 가진 row를 제한할 수 있습니다. 예로 LIKE 가 있죠.
예로, 튜토리얼의 'pets' table에서 3번째 row를 선택한다면 아래와 같은 query가 작성되어야 합니다.

하나 더. %는 문자의 개수와 상관없이 대체가능하게 해주는 "wildcard"입니다.
이 방법도 3번째 row를 가져오게 해줍니다.
query = """
SELECT *
FROM `bigquery-public-data.pet_records.pets`
WHERE Name LIKE '%ipl%'
"""
'posts_questions' table에서 'id', 'title', 'owner_user_id' column을 선택하세요
대신 'tags' column에 "bigquery"라는 단어가 들어있는 row는 무조건 제외하세요 ("bigquery-sql"도 안 됩니다.)
# Your code here
questions_query = """
SELECT id, title, owner_user_id
FROM `bigquery-public-data.stackoverflow.posts_questions`
WHERE tags LIKE '%bigquery%'
"""
# Set up the query (cancel the query if it would use too much of
# your quota, with the limit set to 1 GB)
safe_config = bigquery.QueryJobConfig(maximum_bytes_billed=10**10)
questions_query_job = client.query(questions_query, job_config = safe_config) # Your code goes here
# API request - run the query, and return a pandas DataFrame
questions_results = questions_query_job.to_dataframe() # Your code goes here
print(questions_results.head())
4th Your first join
"bigquery" 관련 질문들의 답변을 'posts_answers' table에서 추출하여 'id', 'body', 'owner_user_id' column을 반환하세요.
-> 모든 column에 a. 으로 어떤 table인지 알려주어야 함!
- tags에 'bigquery'를 가진 질문에 대한 각 답변을 하나의 row로 받아와야 합니다.
- 'posts_questions' table의 'tags' column에서 그 질문의 tag를 가져올 수 있습니다.
Hint: Do an INNER JOIN between bigquery-public-data.stackoverflow.posts_questions and bigquery-public-data.stackoverflow.posts_answers.
Give post_questions an alias of q, and use a as an alias for posts_answers. The ON part of your join is q.id = a.parent_id.
answers_query = """
SELECT a.id, a.body, a.owner_user_id
FROM `bigquery-public-data.stackoverflow.posts_questions` AS q
INNER JOIN `bigquery-public-data.stackoverflow.posts_answers` AS a
ON q.id = a.parent_id
WHERE q.tags LIKE '%bigquery%'
"""
# Set up the query (cancel the query if it would use too much of
# your quota, with the limit set to 1 GB)
safe_config = bigquery.QueryJobConfig(maximum_bytes_billed=10**10)
answers_query_job = client.query(answers_query, job_config=safe_config)
# API request - run the query, and return a pandas DataFrame
answers_results = answers_query_job.to_dataframe()
# Preview results
print(answers_results.head())
5th Answer the question
많은 질문에 답한 사용자 목록이 필요합니다.
"bigquery"를 담은 tag를 가진 질문에 답변을 적어도 한 번 이상 했던 사용자들을 row에 두어 추출하세요.

결과에 들어갈 column은
- 'user_id' : 'posts_answers' table에서 가져온 'owner_user_id' column을 포함
- 'number_of_answer' : "bigquery"와 관련된 질문에 답변한 사용자의 수
bigquery_experts_query = """
SELECT a.owner_user_id AS user_id, COUNT(1) AS number_of_answers
FROM `bigquery-public-data.stackoverflow.posts_questions` AS q
INNER JOIN `bigquery-public-data.stackoverflow.posts_answers` AS a
ON q.id = a.parent_id
WHERE q.tags LIKE '%bigquery%'
GROUP BY user_id
"""
# Set up the query
safe_config = bigquery.QueryJobConfig(maximum_bytes_billed=10**10)
bigquery_experts_query_job = client.query(bigquery_experts_query, job_config=safe_config)
# API request - run the query, and return a pandas DataFrame
bigquery_experts_results =bigquery_experts_query_job.to_dataframe()
# Preview results
print(bigquery_experts_results.head())
SELECT에 사용할 column은 꼭 GROUP BY 또는 aggregation 함수에 사용해야함을 주의! 여기선 user_id가 문제였음.
6th Building a more generally useful service
웹사이트에서 백앤드처럼 활동하려면 아래의 query가 도움이 될 겁니다.
아래의 함수는 StackOverflow에서 하나의 topic에 대해 답변을 작성한 user의 id를 가진 dataframe을 반환합니다.
user_id와 number_of_answers column을 가진 dataframe이죠.
parameter에서 topic은 문자열이며, client는 stackoverflow dataset과 연결을 특정지어주는 client object입니다.
def expert_finder(topic, client):
'''
Returns a DataFrame with the user IDs who have written Stack Overflow answers on a topic.
Inputs:
topic: A string with the topic of interest
client: A Client object that specifies the connection to the Stack Overflow dataset
Outputs:
results: A DataFrame with columns for user_id and number_of_answers. Follows similar logic to bigquery_experts_results shown above.
'''
my_query = """
SELECT a.owner_user_id AS user_id, COUNT(1) AS number_of_answers
FROM `bigquery-public-data.stackoverflow.posts_questions` AS q
INNER JOIN `bigquery-public-data.stackoverflow.posts_answers` AS a
ON q.id = a.parent_Id
WHERE q.tags like '%{topic}%'
GROUP BY a.owner_user_id
"""
# Set up the query (a real service would have good error handling for
# queries that scan too much data)
safe_config = bigquery.QueryJobConfig(maximum_bytes_billed=10**10)
my_query_job = client.query(my_query, job_config=safe_config)
# API request - run the query, and return a pandas DataFrame
results = my_query_job.to_dataframe()
return results'Machine Learning > [Kaggle Course] SQL (Intro + Advanced)' 카테고리의 다른 글
| How to Define Analytic/window Functions (0) | 2021.01.15 |
|---|---|
| JOINs and UNIONs (0) | 2021.01.14 |
| AS & WITH (0) | 2020.12.07 |
| ORDER BY (0) | 2020.12.05 |
| HAVING vs WHERE (0) | 2020.12.05 |