Introduction
Data leakage (or leakage)는 training data에 target에 대한 정보가 포함되어 있음에도, 비슷한 데이터에서 예측하지 못할 때 발생합니다. 즉, leakage는 model로 decision(결정)을 내리기 시작할 때까지는 정확해보이지만 이후에는 model이 매우 부정확한 값을 산출하게 합니다.
leakage에는 두 종류가 있습니다.
Type 1) Target Leakage
예측 시에 사용할 수 없는 data가 포함된 상태에서 예측을 할 때 발생
그러니 데이터를 이용할 수 있는 타이밍이나 정방향 순서대로(chronological order)의 관점에서 생각해봐야 함

위의 표로 pneumonia에 걸릴 사람이 누군인지 예측해봅시다.
사람들은 회복을 위해 pneumonia에 걸린 후에 항생제를 먹죠.
위의 표는 각각의 column들끼리 깊은 상관관계를 가지고 있습니다.
그러나 'took_antiboitic_medicine'값은 'got_pneumonia'값에 따라 빈번히 바뀝니다. 이것이 바로 Target Leakage입니다.
model을 보고 알 수 있는 점 하나는, 'took_antibiotic_medicine'이 False이면, pneumonia에 걸리지 않는다는 사실입니다.
valid_data는 train_data와 같은 출처로부터 나오기에, 이 패턴은 valid_data에서도 나타날 테며,
model의 validation score(or cross-validation) scores는 아주 높을 것입니다.
그러나 모델이 실세계에 적용되면 매우 부정확해질 수 있습니다.
왜냐하면 pneumonia에 걸릴 환자임에도 아직 항생제를 받지 못할 수 있습니다.
그들의 미래의 건강에 대한 예측이 필요할 때 말이죠.
이러한 data leakage를 방지하기 위해,
모든 변수는 target value가 실현화된 후 생성되거나 갱신된 모든 변수들을
무조건 제외/배제해야 합니다.
즉, 예측 이후의 생성된 데이터는 쓸 수 없다는 말이죠. 주의!
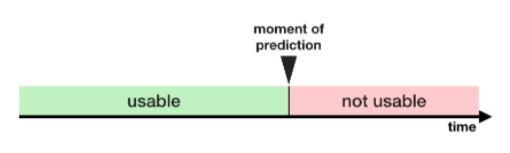
Type 2) Train-Test Contamination
이 leakage는 valid_data와 train_data를 구별할 때 조심하지 않으면 발생합니다.
validation의 의미는 model이 이전에 적용되지 않은 data에서도 제대로 동작하는지 확인하는 것입니다.
valid_data가 전처리 과정에 영향을 줄 경우 이 process를 미묘하게 손상시킬 수 있습니다.
이는 때때로 train-test contamination이라 부릅니다.
예로 'train_test_split()'을 호출하기 전 전처리 과정(like fitting an imputer for missing values)을 한다고 상상해봅시다.
model은 아마도 좋은 validation score를 산출할 것이면 당신도 그 모델에 대해 강한 확신을 얻겠죠.
하지만 정작 결정을 내릴 때 적용해보면(deploy it to make decisions) 그 성능은 현저히 떨어집니다.
결국, 당신은 valid_data와 예측에 사용할 test data를 데이터를 합쳤습니다.
그래서 특정 data에 대해서는 잘 동작하지만, 안타깝게도 새로운 값에 대해선 일반적인 결과를 산출하지 못하죠.
더 복잡한 feature engineering에서, 이 문제는 점점 더 감지하기 힘들어지기에 위험합니다.
만약 validation이 simple train-test split을 기반으로 되어있다면, validation data에서 그 어떤 타입의 fitting이건 모두 제외시키세요. 오직 전처리 단계의 fitting만 포함시켜둡시다. 이러면 scikit-learn의 pipeline을 사용하기 훨씬 쉬워집니다. cross-validation을 사용할 시, 전처리 과정에서 pipeline을 포함시키는 건 더욱더 중요합니다!!
Example
여기선 target leakage를 감지하고 삭제하는 한 가지 방법을 배울 것입니다.
신용카드 신청 정보에 대한 dataset을 이용하겠습니다. 최종 결과는 'X' DataFrame에 저장되어 있는 각 신용 카드 신청에대한 정보입니다. 어떤 신청이 접수되는지를 예측할 것이며 이는 'y' Series에 저장되어 있습니다.
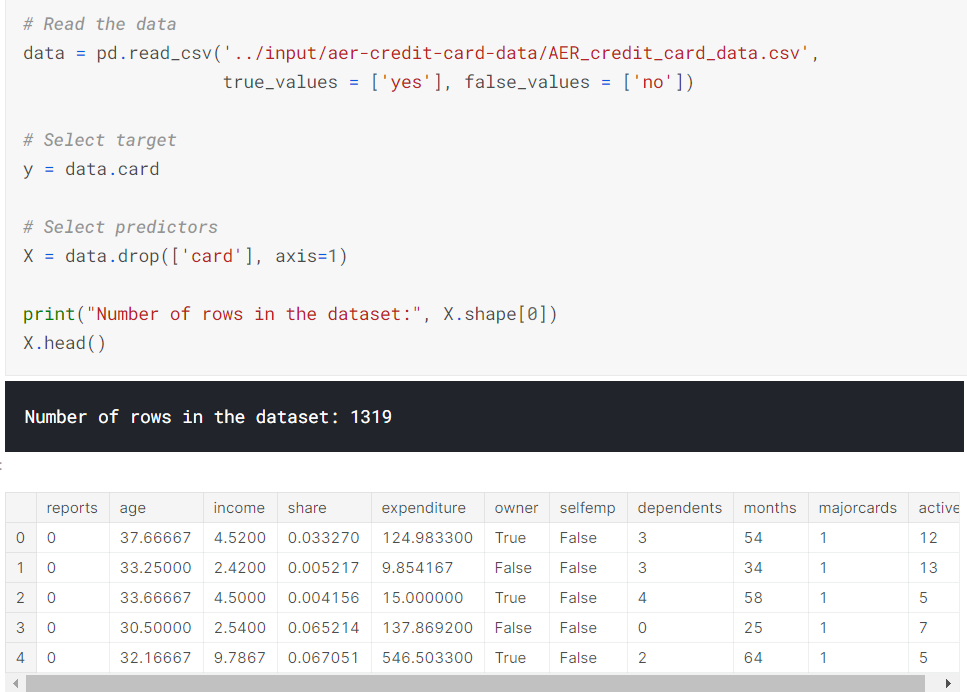
보시다시피 작은 데이터이기에, cross-validation으로 model quality를 측정해봅시다.
from sklearn.pipeline import make_pipeline
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
# Since there is no preprocessing, we don't need a pipeline (used anyway as best practice!)
my_pipeline = make_pipeline(RandomForestClassifier(n_estimators=100))
cv_scores = cross_val_score(my_pipeline, X, y,
cv=5,
scoring='accuracy')
print("Cross-validation accuracy: %f" % cv_scores.mean())
#Cross-validation accuracy: 0.981052
지금까지 courses를 거쳐오며, (상식적으로) 98%의 정확도를 갖는 model를 찾기란 쉽지 않다는 것을 아실 겁니다.
일어나기에 한다지만 흔하지 않기에, target leakage에 대비하여 data를 좀 더 면밀히 검사해야 합니다.
data를 요약하자면 다음과 같습니다.

몇몇 데이터가 의심스럽지 않으신가요?
예로 'expenditure'은 카드 지출 또는 이전에 사용한 카드의 지출을 의미하지 않나요?
이러한 관점에서, basic data를 비교해보는 것은 매우 도움이 됩니다.
expenditures_noncardholders = X.expenditure[~y]
print('Fraction of those who did not receive a card and had no expenditures: %.2f' \
%((expenditures_noncardholders == 0).mean()))
print('Fraction of those who received a card and had no expenditures: %.2f' \
%(( expenditures_cardholders == 0).mean()))
#Fraction of those who did not receive a card and had no expenditures: 1.00
#Fraction of those who received a card and had no expenditures: 0.02
위를 보시면 카드를 받지 못한 사람은 지출이 없으며, 반면에 그 중 2%만이 카드를 받았음에도 지출이 없습니다.
우리의 model이 높은 정확도를 보인다는 건 놀라운 일이 아니죠. 그러나 이는 target leakage가 의심되네요.
'expenditures'는 아마도 그들이 등록한 카드를 통하여 발생한 지출을 의미할 테니깐요.
'expenditure'에 따라 부분적으로 'share' 값이 결정되기에 이것도 제외시켜야 합니다.
'actvie'와 'majorcards' 변수는 설명으로만 보면 아주 약간은 깔끔해보이지만 걱정해보아야 할 것 같아요.
대부분의 상황에서 더 많은 data를 찾기 위해 data를 생성한 사람들을 추적할 수 없다면 후회하는 것보단 안전한 것이 낫습니다.
자, target leakage 없이 model를 돌려봅시다.
# Drop leaky predictors from dataset
potential_leaks = ['expenditure', 'share', 'active', 'majorcards']
X2 = X.drop(potential_leaks, axis=1)
# Evaluate the model with leaky predictors removed
cv_scores = cross_val_score(my_pipeline, X2, y,
cv=5,
scoring='accuracy')
print("Cross-val accuracy: %f" % cv_scores.mean())
#Cross-val accuracy: 0.830165
정확도가 조금 떨어져서 실망하실지도 모르겠네요.
그래도 우린 새로운 값에서도 80%에서의 확률로 옳은 답을 내놓을 수 있다고 예상할 수 있습니다.
반면에 위의 leaky model은 아마도 이보다 더 좋지 않았을 겁니다.
(cross-validation score의 높고 뚜렷한 것이 의심스러워야 합니다!)
Conclusion
Data leakage는 수십억 달러의 손실을 줄 수 있습니다.
train_data와 valid_data를 조심스럽게 분리하는 것이 train-test contamination을 방지하는데 최고의 방법입니다.
pipelines는 이러한 분리를 도와줄 수 있습니다.
마찬가지로 조심성(caution), 상식(common sense), data 탐구(exploration) 등을 해보는 것도 target leakage를 찾는데 도움이 될 수 있습니다.
Exercise
1. The Data Science of Shoelaces
나이키에서 당신을 데이터 사이언스 컨설턴트로 고용하여 비용과 신발 원자재를 절감해주어야 한다고 합시다.
첫번째 과제는 나이키 소속 직원 중 한 분이 만든 model를 보며 매달 몇 개의 신발끈이 필요한지 예측하는 것입니다.
머신러닝 모델에 사용할 features는 다음과 같습니다.
- 이번 달 (January, February, etc)
- 이전 달에서 광고에 쓰인 지출 비용 (advertising expenditures)
- 이번 달에 일어난 다양한 거시경제적(macroeconomic) 특징(예로 실업률)
- 이번 달에 사용할 가죽(leather)의 양
회사에서 얼마나 많은 가죽이 사용되었는지에 대한 feature를 추가한다면 완벽하게 정확한 모델을 얻을 수 있을 것입니다. 그러나 그 feature를 제외해야만 적당히(moderately) 정확할 겁니다.
조만간 이 사실을 알게 될 거예요. 그들이 사용한 가죽의 양이 그들이 생산한 신발의 수의 완벽한 지표거든요.
즉,(in turn tells) 얼마나 많이 신발끈이 필요한 지 알 수 있다는 말이죠.
(가죽->신발->신발끈 => 가죽->신발끈)
가죽을 feature로 사용하면 그 점이 data leakage의 원인이 되지 않을까 의심해봅시다.
만약 당신의 대답이 "it depends, 그에 따라 좌우된다'라고 판단하면 무엇에 따라 좌우되는 것일까요?
답은 data를 어떻게 수집하였는지 그 방법에 대한 세부사항에 따라 좌우됩니다.
이번 달에 얼마나 많은 가죽이 필요한 지 꼭 이번 달 '초'에 결정해야 할까요?
그렇게 생각한다면, 그것도 괜찮아요.
그렇지만 그 값은 해당 달을 거치면서 정해지기에, 예측할 때는 사용할 수 없어요. (Target Leakage)
그래도 초기에 추측은 할 수 있죠. 하지만 나날이 조금씩 값이 변하기에, 실제 사용된 양을 feature로 쓸 수 없습니다.
2. Return of the Shoelaces
가죽의 양을 아는 방법으론 그들이 실제로 얼마나 사용했는지 보는 것이 아닌 '나이키가 얼마나 가죽을 주문했는지 그 양'을 보아도 되겠죠. 이는 해당 달에 신발끈이 몇 개 필요한지를 보여주는 지표가 될 것입니다.
leakage problem이 있을지 아닐지에 대한 당신의 답변이 위와 같은 다른 방식의 생각을 쓴다면 바뀔까요?
만약 당신의 대답이 "it depends, 그에 따라 좌우된다'라고 판단하면 무엇에 따라 좌우되는 것일까요?
괜찮을 수도 있다만 그들이 처음 주문한 물품이 가죽인지, 신발끈인지에 따라 좌우됩니다.
만약 그들이 가죽보다 신발끈을 먼저 주문했다면, 신발끈이 얼마나 필요한지 예측하는데 주문한 가죽의 양을 알 필요가 없죠. 만약 가죽을 먼저 주문했다면, 신발끈의 수를 정하기 전에 그 수량을 알 수 있기에 괜찮겠지요.
3. Getting Rich With Cryptocurrencies(가상화폐)?
나이키에서 지출 비용을 절감하는데 큰 도움이 되었다며 보너스를 주었다고 해봅시다.
당신의 친구가 말하길, 내가 그 보너스를 백만달러로 바꿔줄 수 있는 모델을 가지고 있다고 하네요.
그 모델의 새로 나온 가상화폐(예로 비트코인, 아니면 그 보다 더 최신의)의 가격을 하루 전에 예측하는 모델이랍니다.
그의 계획은 가상화폐를 사서 모델에게 그 가격이 오를 때를 알려달라고 하는 것이지요.
그의 모델에서 중요한 feature들은 다음과 같습니다.
- 현재 화폐의 가격
- 24시간 전에 팔린 화폐의 양
- 24시간 전과 지금의 화폐 가격의 변화량
- 1시간 전과 지금의 화폐 가격의 변화량
- 24시간 동안 화폐와 관련된 트위터 mention들의 수
달러에 비해 가상화폐의 가치가 100달러 이상 오르내렸습니다. 그 친구가 말하길, 이 점이 바로 그의 모델이 정확도를 증명한다고 하네요. 그러니 model이 곧 오를 것이라고 말할 때마다 화폐를 사면서 투자해보자고 합니다.
그 사람의 말이 맞나요? 그의 모델에 문제가 있다면 그것은 무엇일까요?
여기엔 leakage의 원인이 될 만한 건 없네요. 위의 features는 예측하는 그 순간에 이용가능해야 하며, train_data로 해본 후 예측 대상(prediction target)이 정해진 후라면 train_data가 변경될 일은 없을 겁니다.
하지만, 조심해야겠지요. 그가 정확성을 설명하는 방법이 과연 맞을까요?
가격이 조금씩만 움직이면 오늘의 가격은 내일의 가격을 정확하게 예측할 수 있지만, 지금이 투자하기 좋은 시기인지는 모르죠. 예로 오늘이 100달러이고, 모델이 예측한 내일의 가격도 100이라면, 모델이 정확해보이긴 하지요.
하지만 모델은 현재 가격보다 가격이 오르는지 내리는지 알 수 없습니다. 내일이 되어봐야 정확히 알 수 있겠지요.
그러므로 더 나은 prediction target은 다음 날의 가격 변동입니다.
가격이 얼마나 오를지 일관되게 예측할 수 있다면, 투자로 수익을 얻을 수 있을 것입니다.
4. Preventing Infections
보건당국에서 휘귀 질병에 대한 수술로 인해 감염될 위험이 있는 환자를 예측하려 합니다. 그 정보를 간호사에게 전달하여 환자들을 관찰할 때 주의하도록 경고할 수 있겠죠.
자 이제 model를 구축해봅시다. model에 쓰일 dataset의 각 행(row)는 수술을 받은 한 환자에 대한 정보입니다. prediction target은 그들의 감염 여부이고요.
일부 외과의사들은 감염의 위험을 높이거나 또는 낮추는 방식의 수술을 할 수 있습니다. 하지만 어떻게 해야 model을 이용하여 외과의사에게 최적의 수술법을 알려줄 수 있을까요?
당신은 기발한 생각이 떠올랐습니다.
1. 각 외과의사가 행한 수술들을 모아 그들 중에서 발생한 감염률을 계산합니다.
2. 각 환자에 대해 수술한 의사가 누구인지 알아내고, 해당 외과의사에 의한 평균 감염률을 feature로 둡니다.
Target leakage가 생길만한 곳이 보이나요?
아니면 Train-test Contamination issue는요?
이는 Target leakage 및 Train-test Contamination 모두 발생하게 됩니다. (주의한다면 둘 다 피할 수도 있습니다.)
특정 환자의 결과(경후)가 외과의사에 의한 감염률에 연관지어질 경우에, Target leakage가 발생합니다. 그러면 해당 환자의 감염 여부에 대한 prediction model를 다시, 다른 곳과 연관지어봐야 합니다. 우리가 예상한 환자가 의전에 받은 수술만을 사용하여 외과의사에 의한 감염률을 계산하면 target leakage를 피할 수 있습니다. train_data에서 각 수술에 대해 외과의사에 의한 감염률을 계산하는 것은 약간 어려울 수 있습니다.
test-set도 포함하여, 이를 모든 외과의사가 행한 수술에 대한 정보를 사용하여 계산한다면, Train-test Contamination이 발생합니다. 그 결과 model은 test-set에서 정확해보이지만 일반적으로 새로운 환자에 대해서는 부정확한 답을 내놓을 것입니다. 이러한 문제가 발생하는 이유는, surgeon-risk, 외과의사의 위험,이란 feature가 test-set에 있기 때문입니다.
Test-set은 새로운 데이터에서 모델이 어떠한 결과를 내놓는지 조사하기 위해 존재합니다. 그러므로 Train-test Contamination은 test set의 목적을 저하시킵니다.
5. Housing Prices
자, 이제 부동산 가격을 예측하는 model을 만들어봅시다. model은 새 주택의 가격을 예측하기 위해 웹사이트에 설명이 추가될 때마다 업데이트된다고 합시다. 여기서는 4개의 feature를 predictors(예측 변수)로 사용할 것입니다.
- 주택의 크기 (in square meters)
- 같은 동네 주택의 평균 매매 가격
- 그 주택의 위도와 경도
- 그 주택의 지하실 유무 여부
train과 validate, model에 사용할 과거의 data(historic data)를 가지고 있습니다.
어느 feature가 leakage의 원인이 될 확률이 높을까요?
답은 2번째, "같은 동네 주택의 평균 매매 가격" feature입니다.
그 이유는 평균 매매 가격이 언제 업데이트되는지 정확한 규칙이 존재하지 않기 때문입니다. 어떻게 미래에 변화할 지 모르기에 Target Leakage에 해당합니다. 극단적으로, 만약 한 집만 팔리고, 예측하려고 한 집이 그 집이라면, 평균 매매 가격은 우리가 예측하려고 하는 가치와 정확히 같을 것입니다. 그러나 일반적으로 판매량이 적은 지역의 경우 이 model은 train_data에서는 높은 정확도를 보이지만 아직 판매되지 않은 집에 대한 예측에서는 낮은 정확도를 보일 것입니다.
6. 결론
leakage가 발생할 수 있는 feature를 잘 집어내셔야 해요!
'Machine Learning > [Kaggle Course] ML (+ 딥러닝, 컴퓨터비전)' 카테고리의 다른 글
| [Kaggle Course] Deep Neural Networks _ nonlinear with ReLU (0) | 2020.12.19 |
|---|---|
| [Kaggle Course] A Single Neuron _ Define a linear model (0) | 2020.12.17 |
| [Kaggle Course] XGBoost (gradient boosting) + Ensemble method (0) | 2020.10.24 |
| [Kaggle Course] Cross-Validation(교차검증) (0) | 2020.10.23 |
| [Kaggle Course] Pipelines + How to make and submit CSV in Kaggle (0) | 2020.10.21 |