이번 튜토리얼에서는 pet_records라는 dataset을 사용합니다.
pets이라 불리는 하나의 table만 가진 dataset입니다.
SELECT ... FROM
하나의 table(FROM) 속에 있는 하나의 column(SELECT)을 선택하는 명령문
FROM에는 꼭 backticks(`)를 써야하는 점 주의! single or double quote NOPE! (',")

WHERE ...
BigQuery dataset은 많이 크기에, 특정 조건에 맞는 rows만 추출하여 사용하게 되는 경우가 많습니다. 그럴 때 WHERE을 사용합니다.

Ex) What are all the U.S. cities in the OpenAQ dataset?
해당 dataset의 미국의 대기 quality가 담겨있습니다.
자 일단, query 실행 및 database에서 원하는 table만 추출하기 위한 setup을 해봅시다.
from google.cloud import bigquery
# Create a "Client" object
client = bigquery.Client()
# Construct a reference to the "openaq" dataset
dataset_ref = client.dataset("openaq", project="bigquery-public-data")
# API request - fetch the dataset
dataset = client.get_dataset(dataset_ref)
# List all the tables in the "openaq" dataset
tables = list(client.list_tables(dataset))
# Print names of all tables in the dataset (there's only one!)
for table in tables:
print(table.table_id)
아래의 코드를 실행하면 'global_air_quality'라는 하나의 table만 담긴 dataset이 나옵니다.
# Construct a reference to the "global_air_quality" table
table_ref = dataset_ref.table("global_air_quality")
# API request - fetch the table
table = client.get_table(table_ref)
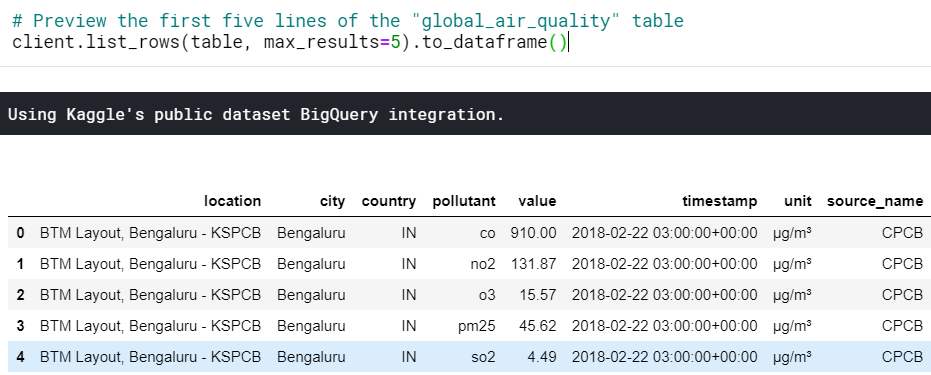
# Preview the first five lines of the "global_air_quality" table
client.list_rows(table, max_results=5).to_dataframe()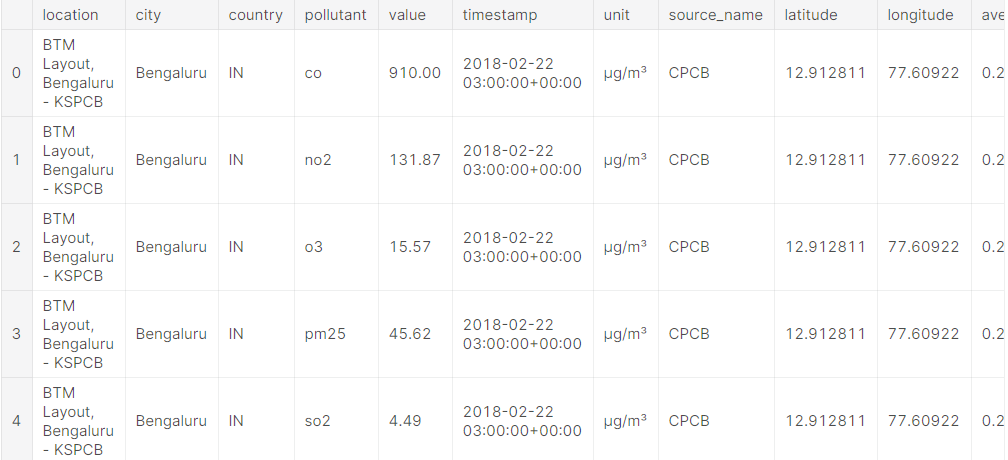
여기서 country가 US인 'city' column의 값들만 가져오는 코드는 아래와 같이 작성합니다.
# Query to select all the items from the "city" column where the "country" column is 'US'
query = """
SELECT city
FROM `bigquery-public-data.openaq.global_air_quality`
WHERE country = 'US'
"""
Submitting the query to the dataset (dataset에 query(조건/명령문) 보내기)
OpenAQ dataset에서 정보를 가져오기 위해 query를 써보려 합니다.
Client object를 생성하여 그 객체에 query() 메소드를 실행합니다.
기초 예제이니 default parameters를 사용했지만, 이외에도 더 궁금하다면 여기를 가보세요.
그 다음엔 생성한 query를 pandas의 DataFrame으로 변환합니다.
# 1st
# Create a "Client" object
client = bigquery.Client()
# 2nd
# Set up the query
query_job = client.query(query)
# 3rd
# API request
#-> run the query, and return a pandas DataFrame
us_cities = query_job.to_dataframe()
# 4th
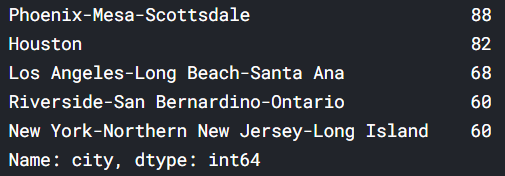
# What five cities have the most measurements?
us_cities.city.value_counts().head()
More queries
여러 개의 column들이 필요하다면 아래와 같이 쉼표( , )를 column 이름 사이에 넣어줍니다.
모두 필요하다면, * 을 넣어주세요.
query_comma = """
SELECT city, country
FROM `bigquery-public-data.openaq.global_air_quality`
WHERE country = 'US'
"""
query_all = """
SELECT *
FROM `bigquery-public-data.openaq.global_air_quality`
WHERE country = 'US'
"""
+) """ double quote를 3개씩 쓰는 이유는, Python 문법에 따라, 줄바꿈을 인식하게 해주기 위해서 입니다.
+) SELECT와 FROM은 꼭 대문자로 하지 않아도 되지만, 가독성에 있어 좋기에, 대문자로 해주세요.
Working with big datasets
BigQuery는 워낙 크기에 한계가 있습니다.
현재 kaggle에서 가장 큰 dataset이 3TB입니다.
Kaggle user는 30일간 5TB를 무료로 사용할 수 있으니 괜찮죠.
그래도 혹여나 한계를 넘지 않도록, 그 방법을 알려드릴게요.
1st) 모든 query의 크기를 조사합니다. - (Hacker News dataset을 예로 들게요)
-> query_name.total_bytes_processed -> byte 단위
# Query to get the score column from every row where the type column has value "job"
query = """
SELECT score, title
FROM `bigquery-public-data.hacker_news.full`
WHERE type = "job"
"""
# Create a QueryJobConfig object to estimate size of query without running it
dry_run_config = bigquery.QueryJobConfig(dry_run=True)
# API request - dry run query to estimate costs
dry_run_query_job = client.query(query, job_config=dry_run_config)
print("This query will process {} bytes.".format(dry_run_query_job.total_bytes_processed))
Tip) query 실행 시 scan할 data 양을 제한하기 위해 parameter를 지정할 수 있어요. 그 limit을 낮게 잡는 방법입니다.
-> safe = bigquery.QueryJobConfig( maximum_bytes_billed = 원하는 data 크기 )
-> client.query ( query, job_config=safe )
# Only run the query if it's less than 1 MB
ONE_MB = 1000*1000
safe_config = bigquery.QueryJobConfig(maximum_bytes_billed=ONE_MB)
# Set up the query (will only run if it's less than 1 MB)
safe_query_job = client.query(query, job_config=safe_config)
# API request - try to run the query, and return a pandas DataFrame
safe_query_job.to_dataframe()
위의 사진은 1MB를 초과했기에, query가 취소되었습니다.
위와 같이 에러를 일으키지 않도록 하려면,
limit을 초과했을 때 query를 취소되지 않도록, 그럼 limit을 더 크고 높게 잡으세요!
#Only run the query if it's less than 1 GB
ONE_GB = 1000*1000*1000
safe_config = bigquery.QueryJobConfig(maximum_bytes_billed=ONE_GB)
# Set up the query (will only run if it's less than 1 GB)
safe_query_job = client.query(query, job_config=safe_config)
# API request - try to run the query, and return a pandas DataFrame
job_post_scores = safe_query_job.to_dataframe()
# Print average score for job posts
job_post_scores.score.mean()
# ->>1.874250078939059
Exercise
Q1. 오염 수치 측정에 'ppm'이란 단위를 사용하는 국가를 선택하는 query를 작성하시오
+) SELECT DISTINCT를 사용하면 해당 국가가 한 번만 선택되는 기능이 추가됨
# sol 1)
first_query = """
SELECT country
FROM `bigquery-public-data.openaq.global_air_quality`
WHERE unit = "ppm"
"""
# sol 2)
# Or to get each country just once, you could use
first_query = """
SELECT DISTINCT country
FROM `bigquery-public-data.openaq.global_air_quality`
WHERE unit = "ppm"
Q2. 오염 수치를 의미하는 'value' column에서 0 값이 들어간 row의 모든 column을 선택하는 query를 작성하시오.
# Query to select all columns where pollution levels are exactly 0
zero_pollution_query = """
SELECT *
FROM `bigquery-public-data.openaq.global_air_quality`
WHERE value = 0
"""# Set up the query
safe_config = bigquery.QueryJobConfig(maximum_bytes_billed=10**10)
query_job = client.query(zero_pollution_query, job_config=safe_config)
Q3. query의 결과를 DataFrame으로 변환하세요.
# API request - run the query and return a pandas DataFrame
zero_pollution_results = query_job.to_dataframe() # Your code goes here
print(zero_pollution_results.head())
SELECT는 groupby()와 비슷해보이지만,
BigQuery는 더 큰 dataset에서 빠르게 동작하기에 그 때는 SELECT를 써야 합니다.
그렇지만 SELECT만으로는 data를 흥미로운 질문에 대한 답을 얻기 위해 조합하기 힘들어요.
그래서 GROUP BY command를 배울 겁니다. groupby()와 비슷한 녀석이죠!
'Machine Learning > [Kaggle Course] SQL (Intro + Advanced)' 카테고리의 다른 글
| AS & WITH (0) | 2020.12.07 |
|---|---|
| ORDER BY (0) | 2020.12.05 |
| HAVING vs WHERE (0) | 2020.12.05 |
| GROUP BY, HAVING & COUNT() (0) | 2020.12.02 |
| Start SQL and BigQuery (0) | 2020.11.28 |