routing algorithm determines end-end-path through network
forwarding table determines local forwarding at this router
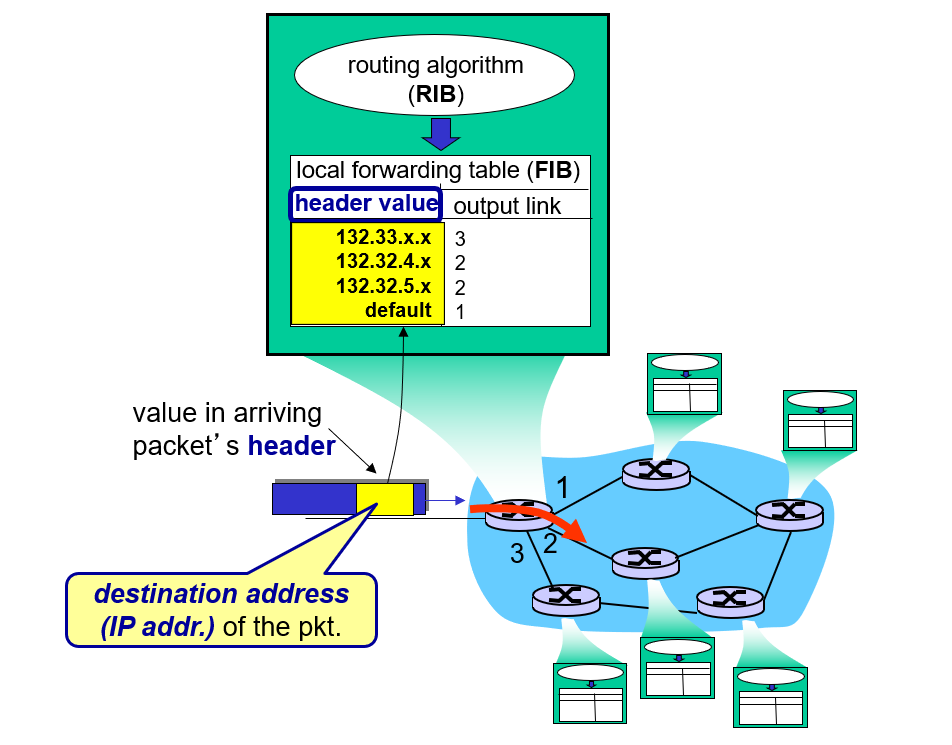
<Data plane> (app data) - local forwarding - 이거 어디로 보낼까?
각 목적지에 대해 어떤 packet을 보낼지 정함
user data를 담은 packet이 input port로 들어오면
FIB를 참고하여 output port를 정하여
다음 router로 넘김
<Control Plane> (routing msg) - end to end path - router에만 들어있음
network-wide logic
data plane에서 사용하는 FIB를 작성할 내용을 마련하는 것
routing protocol에 따라서 이웃한 network와 routing msg를 주고 받으며
이 network에 어떤 node와 link가 있고 상태는 어떤지 알아둠
그 상태 정보를 가지고 RIB를 계산
이 RIB(Routing Table)는 FIB를 작성하는 자료로 사용

!!
네트워크 계층은 호스트와 라우터에 모두 탑재되는 프로토콜 계층이다.
단, 호스트에는 네트워크 계층 중 데이터 플레인에 속하는 부분만 탑재된다.
Two control-plane approach
- traditional routing algorithm (per-router) : 각 router에 의해서 분산적으로 구현…?
- SDN : software-defined networking (logically centralized) :
- 원격 서버가 control plane 역할을 하여 RIB를 계산
- Open programmable interface
- OpenFlow : SDN 방식의 표준 프로토콜
per-router control plane
!! control plane과 data plane이 같은 장치에!
각각의 routing algorithm component는
모든 router에 들어있고
이들 모두 서로 소통
둘 다 같은 device에 존재
대신 제약점은 destination-based forwarding만 가능
오직 header에 들어있는 목적지 주소만 경로를 지정

Logically centralized control plane
!! control plane과 data plane이 다른 장치에!
router 서로 간이 아닌 remote controller가 총체적으로 판단
그래서 control plane은 server에 두어 서로 다른 device에 존재
각 계산이 장치 별로 독립적으로 이뤄짐...

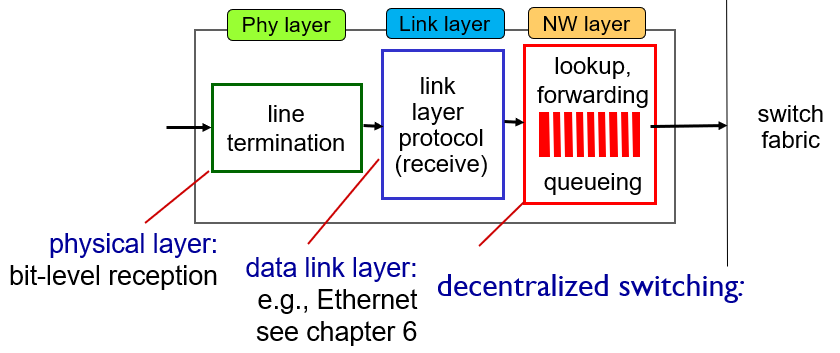
Router Architecture Overview
per-router control plane router에서의 구조
control plane은 소프트웨어로 구현되기에 miliisecond 단위로 천천히 동작
data plane은 빠를 수록 router가 지원하는 bandwidth가 커지기에 nano 초단위로 동작
router를 구성하는 하드웨어
1. routing processor - in control plane
2. switching fabric - in data plane
3. input port - in data plane
4. output port - in data plane

여기서 설명하는 port는 하드웨어 네트워크 카드 꼽는 physical port…?
저기 line card에 port 들이 존재
OSPF process가 RIB Table을 계산

Switching fabric
input buffer 속 packet을 적절한 output buffer로 이동
!! switching rate
n개의 line으로 부터 packet이 들어온다면
가장 이상적인 경우 대기 없이 바로 보내는 경우 (n개 입력에 n times line rate)
그렇기에 측정 방법은 input/output line rate
3종류의 switching fabrics
memory : 꼭 memory를 거쳐감
bus : 한 번의 하나의 input만 모든 아이와 공유된 bus를 점유. (broadcasting 가능)
crossbar : 여러 입력이 동시에 뽑아 나갈 수 있다

Switching via memory
1세대 router 방식
memory access는 CPU를 거쳐야하기에 CPU가 switching도 관여하게 됨
입력->memory, memory->output
총 2번의 bus crossing이 필요
속도는 system bus에 의해 결정됨
Switching via A bus
system bus와는 다른 독립적인 bus를 따로 두어 memory를 거치지 않고 이동
모든 input이 이 bus를 점유하려고 경쟁하기 위해 이에 대한 알고리즘이 있음
switching speed는 bus bandwidth에 의해 결정됨
bus crossing은 한 번만
Cisco 5600은 32Gbps를 사용. 이는 access나 enterprise router에 충분한 속도
Switching via interconnection network (crossbar)
bus bandwidth 제한 극복
여러 모양이 있음
Cisco 12000은 60Gbps를 사용
multiple packet in parallel,
서로 다른 입력들이 서로 다른 output 포트로 가려고 할 때만!
두 패킷이 서로 같은 목적지를 향하면 기다려야 함
bus를 이용한 switching fabric의 경우
한 번에 하나의 input port에서만 output port로
datagram이 이동할 수 있는 반면,
cross bar switch를 switching fabric로 이용하면
여러 input port가 동시에 output port로
datagram을 전달할 수도 있다.
다만, 서로 다른 input port에 도착한 datagram 중
destination output port가 다른 것만 동시에 이동 가능

Router : Input/Output Port

router에서는 input port와 output port에서
모두 queueing이 발생할 수 있는데,
input port에서는 datagram arrival rate를
switching fabric의 switching rate가 따라가지 못하는 경우 queueing이 발생하고,
output port에서는 transmission rate가
switching fabric의 switching rate를 따라가지 못하는 경우 queueing이 발생한다.
Input port function
switch fabric에서 당장 처리할 수 없다면
input port buffer에서 잠시 보관
이로인해 queueing delay나 loss by overflow 발생 가능
목표 : line speed로 input port processing 처리하기
Head-of-the-Line (HOL) blocking
input port의 head에 있는 모든 packet 들은
목적지가 같이 않는 한 즉시 switching함

그런데 목적지가 서로 같다면
세번째 줄에 빨강 뒤에 초록이 앞의 빨강 나가기를 기다리게 됨
만약 세번째 빨강이 먼저 나갔다면
첫번째 빨강이랑 초록색이 같이 나갈 수 있었을 텐데
Output Port

나갈 때도 output port의 queueing buffer를 거쳐야 함
output line speed(transmission rate)보다 fabric이 더 빠르게 도착한 경우
packet scheduler는
큐에 들어간 datagram을 선택하여 전송하여
quality-of-service 를 보장
- internet은 FCFS - first come first serve
- other network는 premium service first로 weighted fair queuing을 지원
bandwidth를 보장하기 위해
단위 시간 당 얼마 정도를 보장할 수 있도록 조절하는 것
+) Priority scheduling – who gets best performance
네트워크의 중립성을 위반
How much buffering at routers?
router의 buffer가 네트워크에 미치는 영향을 알아보자
RFC3439에서
각 router의 buffer크기를
“typical” RTT와 link capacity C에 비례하여 설정하라
long and fat 할 수록 buffer를 크게 잡자

TCP flow는 wait를 할 수 있기에,
서로 statistical하게 multiplexing할 수 있기에,
굳이 이만큼 worst case로 두지 않아도 된다.
서로 rate를 adjust하고 조정할 수 있음.
'CS > Network' 카테고리의 다른 글
| Generalized Forward and SDN - OpenFlow (0) | 2021.12.04 |
|---|---|
| IP : Internet Protocol (0) | 2021.12.04 |
| Overview of Network Layer (0) | 2021.12.04 |
| 3-6 TCP detecting loss & Fairness & ECN (0) | 2021.12.03 |
| 3-5 TCP Congestion Control (0) | 2021.12.03 |