새로운 데이터셋을 보면 당황스럽죠. 수천개의 feature를 설명 없이 해석하는 건 어렵습니다.
이럴 때, featrue utility metric으로 순위를 구성하면 좋습니다.
이 함수는 feature와 target 사이의 연관성을 측정해줍니다. 그 다음에 유용한 featrues를 모아 작은 set을 만듭니다.
이 metric은 "mutual information"이라고 부릅니다.
두 개 사이의 관계를 측정하는 상관관계입니다. 장점은, correlation은 오직 선형 관계만 감지하지만, 이 방법은 모든 종류의 관계를 감지합니다.
정리하여, mutual information은 모델이
- 사용하고 해석하기 쉽거나
- 계산 과정에서 효율성이 보이거나
- 이론적으로 잘 만들어졌거나
- 과적합을 예방하거나
- 모든 종류의 관계를 감지할 수 있다면
사용할 수 있습니다.
Mutual Information and What it Measures
mutual information(MI)은 불확실성이란 용어의 관계를 설명해줍니다.
두 개 사이의 MI는 한 쪽의 지식이 다른 쪽에 대한 불확실성을 감소시키는 정도에 대한 척도입니다.
불확실성은 entropy 이론에서 나온 단위를 사용하여 측정합니다. 변수의 entropy는 대략, 다음을 의미합니다. "얼마나 많은 yes or no 질문이 있어야 변수의 출현 빈도를 평균에 비추어 설명할 수 있는가?" 같은 질문철머요.
더 많이 물어볼수록 변수에 대해 점점 확신하지 못하게 됩니다.
Mutual information은 target에 대해 대답하려면 feature가 얼마나 많은 질문이 필요한 지에 대한 것입니다.
하나의 feature의 값을 알고 있다면, 얼마나 목표값에 대해 자신감을 가질 수 있나요?
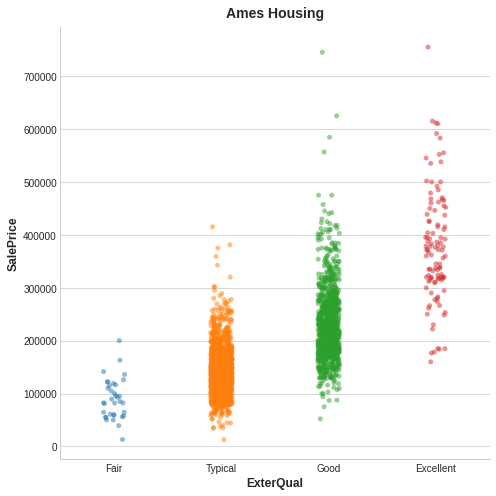
Ames Housing data 예제를 봅시다. 사진은 집의 외형의 퀄리티와 팔린 가격 사이의 관계를 보여줍니다.
각 점은 하나의 집을 의미합니다.
ExterQual 값을 앎으로써 SalePrice에 대응하는 특정 값에 대해 확신을 가질 수 있습니다. ExterQual의 각각의 카테고리는 특정 범위 안에서 SalePrice으로 집중되는 경향이 있습니다.
ExterQual과 SalePrice의 mutual information은 ExterQual의 4가지 값을 차지하는 SalePrice의 불확실성의 평균 감소량입니다.
예를 들어, Fair은 Typical보다 덜 나타나기에 Fair의 MI 점수 속 가중치는 상대적으로 낮습니다.
Interpreting Mutual Information Scores
Mutual information의 최솟값은 0.0입니다. MI가 0이면 두 변수는 독립적입니다. 한 변수가 다른 변수를 설명할 수 없는 상태죠. 역설적으로 이론적으로는 MI에는 상한선이 없습니다. 그럼에도 불구하고 연습에서는 2.0보다 큰 수는 흔하지 않습니다. (MI는 로그 단위이기에 매우 느리게 증가합니다.)
다음 사진은 target과 하나의 feature의 연관성의 종류와 정도에 따른 MI 값의 변화를 보여줍니다.
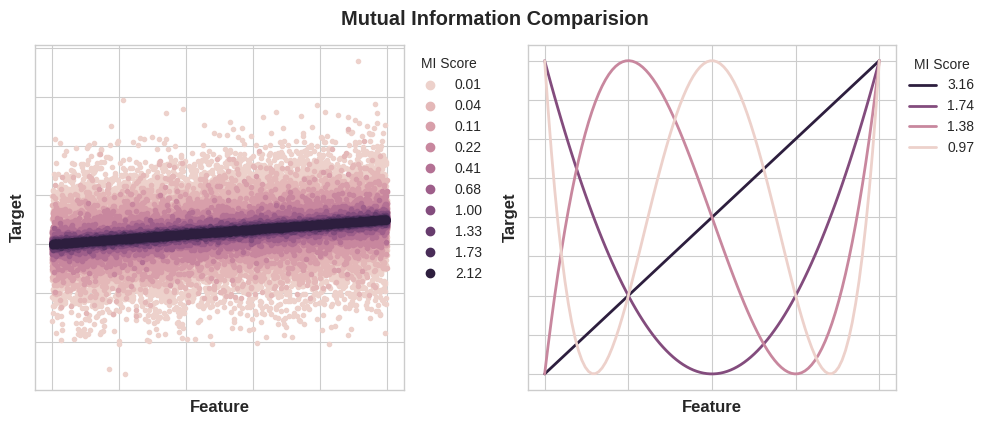
MI를 적용할 때 주의할 점이 있습니다.
- MI는 target의 예측 변수로 feature의 상대적인 잠재력을 이해하는데 도움이 됨
- 하나의 feature가 다른 feature와 상호작용할 때 더욱 도움이 됨. MI는 features의 상호관계는 감지하지 못하며 이는 univariate metric으로 함
- feature의 실제적인 유용함은 모델에 따라 결정됨. feature는 target과의 관계가 모델이 배울 수 있는 관계일 정도까지만 유용함. 왜냐면 feature가 높은 MI 점수를 갖는다고 해서 모델이 해당 정보로 모든 작업을 수행할 수 있지 않음. 연관성을 드러내려면 먼저 feature를 변환해야 함.
Example - 1985 Automoblies
automobile 데이터셋은 1985년도의 193개의 차종에 대한 정보가 담겨 있습니다. 목표는 23개의 feature로 차의 가격(price)를 예측하는 것입니다. feature로는 make, body_style, horsepower 등이 있습니다.
이번에는 Mutual information으로 features의 순위를 매기고 시각화하여 결과를 관찰해보려합니다.
데이터와 라이브러리를 불러옵시다
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
plt.style.use("seaborn-whitegrid")
df = pd.read_csv("../input/fe-course-data/autos.csv")
df.head()

scikit-learn 속 MI는 이산적인 features와 연속적인 features를 구별해줍니다. float 형은 절대 이산적일 수 없듯이요.
카테고리 변수(object or categorial dtype)은 이산적인 변수로 다뤄져 label encoding을 거칠 수 있습니다.
X = df.copy()
y = X.pop("price")
# Label encoding for categoricals
for colname in X.select_dtypes("object"):
X[colname], _ = X[colname].factorize()
# All discrete features should now have integer dtypes (double-check this before using MI!)
discrete_features = X.dtypes == int
scikit-learn는 feature_selection 안에 두가지의 MI metrics를 가지고 있습니다.
하나는 mutual_info_regression으로 실제값들의 target을 위한 것이며,
다른 하나는 mutual_info_classif로 categorical targets을 위한 것입니다.
우리의 목표인 price는 실제 값입니다. 그렇기에 이에 맞게 MI score를 계산하여 dataframe 형식으로 보기 좋게 출력합시다.

from sklearn.feature_selection import mutual_info_regression
def make_mi_scores(X, y, discrete_features):
mi_scores = mutual_info_regression(X, y, discrete_features=discrete_features)
mi_scores = pd.Series(mi_scores, name="MI Scores", index=X.columns)
mi_scores = mi_scores.sort_values(ascending=False)
return mi_scores
mi_scores = make_mi_scores(X, y, discrete_features)
mi_scores[::3] # show a few features with their MI scores
def plot_mi_scores(scores):
scores = scores.sort_values(ascending=True)
width = np.arange(len(scores))
ticks = list(scores.index)
plt.barh(width, scores)
plt.yticks(width, ticks)
plt.title("Mutual Information Scores")
plt.figure(dpi=100, figsize=(8, 5))
plot_mi_scores(mi_scores)
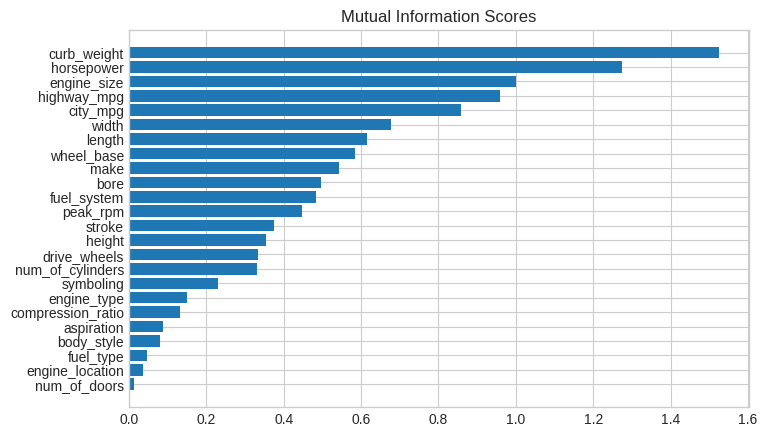
데이터 시각화를 해주면 유틸리티의 순위를 확인하기 좋습니다. 좀 더 자세히 봅시다.
예상한대로 curb_weight feature는 높은 점수를 가지고 있으며 목표인 price와 강한 관계에 놓여 있습니다.
sns.relplot(x="curb_weight", y="price", data=df);
fuel_type feature는 꽤 낮은 MI 점수이지만 사진에서 확인은 가능합니다.
horsepower feature 내에서 서로 다른 추세를 가진 두 개의 price 집단을 명확하게 구분해줍니다.
이는 fuel_type이 상호작용 효과에 기여한다는 점, 무조건 중요하진 않다는 점을 증명합니다.
feature를 결정하기 전에는 MI score는 중요하지 않습니다. 가능성이 있는 모든 상호작용의 효과를 살펴보는 것이 좋습니다.
sns.lmplot(x="horsepower", y="price", hue="fuel_type", data=df);
데이터 시각화는 feature-engineering에서 좋은 관찰 도구입니다. mutual information과 같은 utility metric를 이용하여 이러한 시각화를 통해 데이터 내의 중요한 관계를 발견해보세요.
Exercise
주택 가격에 관한 데이터 속 특징들을 추려낸 뒤, mutual information 점수와 interaction plots를 이용하여 발전시켜보려 합니다.
Setup
# Setup feedback system
from learntools.core import binder
binder.bind(globals())
from learntools.feature_engineering_new.ex2 import *
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.feature_selection import mutual_info_regression
# Set Matplotlib defaults
plt.style.use("seaborn-whitegrid")
plt.rc("figure", autolayout=True)
plt.rc(
"axes",
labelweight="bold",
labelsize="large",
titleweight="bold",
titlesize=14,
titlepad=10,
)
# Load data
df = pd.read_csv("../input/fe-course-data/ames.csv")
# Utility functions from Tutorial
def make_mi_scores(X, y):
X = X.copy()
for colname in X.select_dtypes(["object", "category"]):
X[colname], _ = X[colname].factorize()
# All discrete features should now have integer dtypes
discrete_features = [pd.api.types.is_integer_dtype(t) for t in X.dtypes]
mi_scores = mutual_info_regression(X, y, discrete_features=discrete_features, random_state=0)
mi_scores = pd.Series(mi_scores, name="MI Scores", index=X.columns)
mi_scores = mi_scores.sort_values(ascending=False)
return mi_scores
def plot_mi_scores(scores):
scores = scores.sort_values(ascending=True)
width = np.arange(len(scores))
ticks = list(scores.index)
plt.barh(width, scores)
plt.yticks(width, ticks)
plt.title("Mutual Information Scores")1) Mutual Information 이해하기
시작하기에 앞서, mutual information 의미를 복습해봅시다. 가져온 데이터를 이용해서요.
features = ["YearBuilt", "MoSold", "ScreenPorch"]
sns.relplot(
x="value", y="SalePrice", col="variable", data=df.melt(id_vars="SalePrice", value_vars=features), facet_kws=dict(sharex=False),
);
그래프에 기반하여, 어느 feature가 SalePrice에서 가장 높은 mutual information 점수를 얻을까요?
바로 YearBuilt입니다. SalePrice 값이 작은 범위로 형성될 수 있기 때문입니다.
MoSold는 그 반대이기에 불가능 합니다.
ScreenPorch도 value가 0에만 집중적으로 모여 있어 평균적인 얘기를 하기엔 부적합합니다.
이 데이터셋에는 78개의 feature가 있습니다. 한 번에 다루기엔 많은 양이죠.
다행히도 우리는 가능성이 높은 기능을 식별하는 방법을 압니다.
make_mi_scores 함수를 이용하여 이 데이터셋의 특징들의 mutual information 점수를 계산해봅시다.
X = df.copy()
y = X.pop('SalePrice')
mi_scores = make_mi_scores(X, y)2) MI 점수 평가하기
이제 아래 코드 속 함수를 이용하여 점수를 평가해봅시다.

상단부와 하단부에 집중해서 봅시다.
print(mi_scores.head(20))
# print(mi_scores.tail(20)) # uncomment to see bottom 20
plt.figure(dpi=100, figsize=(8, 5))
plot_mi_scores(mi_scores.head(20))
# plot_mi_scores(mi_scores.tail(20)) # uncomment to see bottom 20

이 점수들이 합리적으로 보이나요?
점수가 높은 feature는 정말로 대부분의 사람들이 집에 있어 중요하다고 생각하는 것인가요?
이 점수가 무엇을 의미하는지 그 주제에 대해 알겠나요?
대부분의 feature에서 공통되는 주제는 다음과 같습니다.
- 위치 : 이웃 사람들 (Neighborhood)
- 크기 : 모든 영역 및 SF feature, 그리고 FullBath 및 GarageCars도 포함 ( Area, SF features, FullBath, GarageCars)
- 품질 : 모든 품질 관련 feature (Qual)
- 연도 : 건축 연도 및 리모델링한 날짜(YearBuilt ,YearRemodAdd)
- 종류 : 스타일에 대한 설명 (Foundation, GarageType)
이러한 특징들은 실제 부동산 거래에서도 중요합니다. (Zillow 사이트 참고)
중요한 특징들에 대한 mutual information 점수가 높아서 좋네요.
즉, 낮은 점수를 받은 feature는 가격에 대해 잘 나타내지 못할 것이며,
보통의 집 구매자에게 관련 없는 정보일 것입니다.
BldgType 기능의 상호작용 효과를 관찰해보려 합니다. 이 feature는 주거의 광범위한 구조를 5가지 범주로 나타냅니다.

sns.catplot(x="BldgType", y="SalePrice", data=df, kind="boxen");
주거의 형태에 대한 MI 점수가 낮았으므로, 이는 주택 가격(SalePrice)을 예상하기 힘든 feature입니다.

하지만 실제 세계에서는 여전히 주거의 형태는 중요한 요인으로 작용하는 것 같습니다. 뭔가 이상하다는 점을 감지한 것이죠.
그래서 GrLivArea와 MoSold 각각에 대해 BldgType과의 관계를 살펴봅시다.
# YOUR CODE HERE:
feature = "GrLivArea"
sns.lmplot(
x=feature, y="SalePrice", hue="BldgType", col="BldgType",
data=df, scatter_kws={"edgecolor": 'w'}, col_wrap=3, height=4,
);
# YOUR CODE HERE:
feature = "MoSold"
sns.lmplot(
x=feature, y="SalePrice", hue="BldgType", col="BldgType",
data=df, scatter_kws={"edgecolor": 'w'}, col_wrap=3, height=4,
);
추세 선이 하나의 범주와 그 다음 범주에서 완전히 다른 양상을 띈다는 것은,
서로 관계가 있는, 상호작용의 효과 속에 놓였다는 것입니다.
3) Interaction 발견하기
그래프를 통해 BldgType는 GrLivArea 또는 MoSold와 상호작용의 관계에 놓여 있나요?
BldgType의 GrLivArea에서 각 범주에 대한 추세선은 매우 다르며, 이는 feature 간의 상호작용의 관계를 의미합니다.
BldgType를 알면 GrLivArea가 SalePrice와 어떻게 관련되는지 자세히 알 수 있으므로
BldgType를 고려해야 할 feature에 포함시켜야 합니다.
그러나 MoSold의 추세선은 거의 동일합니다.
이는 BldgType을 알기에 유용하지 않습니다.
고려해야 하는 feature들을 목록으로 정리해보겠습니다.
다음 실습에서는 높은 가능성이 있다고 식별된 feature의 조합을 통해
보다 유용한 feature 집단을 구축할 것입니다.
MI 점수가 높은 10가지 feature는 다음과 같습니다.
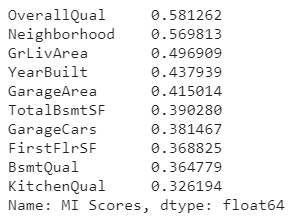
정리
오늘 배운 내용은 방금 전 사진처럼 MI 점수가 높은 feature만 고려할 필요가 없다는 것입니다.
점수가 높은 feature와 관련 있는 feature,
특히 상호작용의 여부 판단으로 알아낸 feature와의 결합도
모델 학습에 유용한 feature 집단을 꾸릴 수 있다는 것입니다
'Machine Learning > [Kaggle Course] Feature Engineering' 카테고리의 다른 글
| What is Feature Engineering (0) | 2021.04.18 |
|---|