Introduction
지금까지 random forest model로 예측했지요.
그 model은 single decision tree보다는 훨씬 나은 성능을 보여줍니다.
수많은 decision tree에 대해서 예측을 한 뒤 평균을 계산하니깐요.
random forest같은 방법을 "ensemble method"라고 부릅니다.
Ensemble methods는 몇 개의 모델들에 대한 예측을 결합하는 것입니다.
random forest의 경우 여러 tree를 사용하여 예측한 뒤 결합했으니 이에 포함되는 것입니다.
이제 우리는 또다른 ensemble method를 배워볼 것입니다.
바로 gradient boosting.
Gradient Boosting

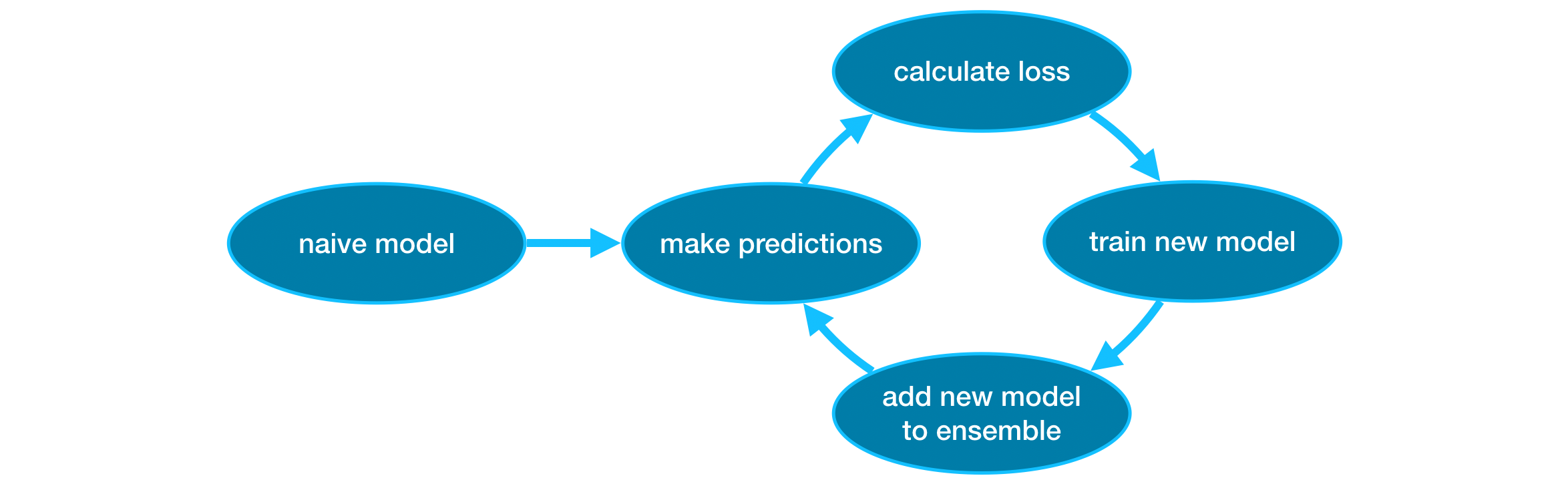
반복적으로 모델을 ensemble에 더하는 cycles을 거치는 방법
('gradient'는 새로운 모델에 속 parameter를 결정하기 위해
loss function에 gradient descent를 사용한다는 의미)
굉장히 단순히 예측하는 단 하나의 모델(a single naive model)를 가지고
ensemble을 초기화함으로써 시작합니다.
(예측이 매우 부정확하더라도, ensemble에 추가하면 이러한 오류가 해결됩니다.(address))
Cycle의 과정
- data set으로 알아낸 각각의 관찰에대한 예측을 생성하기 위해 current ensemble을 사용.
- 예측을 하기 위해 ensemble 속 모든 모델로부터 구해낸 예측을 더합니다.
- 이러한 예측들은 loss function (ex. mean squared error)를 계산하는데 사용됩니다.
- 이 다음으로는, ensemble에 추가된 새로운 모델에 fit해둔 loss function을 사용합니다.
- model의 parameters를 결정해두었기에, ensemble에 대한 새로운 모델은 loss를 줄여줍니다.
- 마침내, ensemble에 새로운 모델을 더하고 위 과정을 반복합니다.
Example
In this example, you'll work with the XGBoost library.
XGBoost stands for extreme gradient boosting, which is an implementation of gradient boosting with several additional features focused on performance and speed.
+) 참고: Scikit-learn에 또다른 여러 버전의 gradient boostring도 있습니다.
(several additional features란 사람이 데이터를 보고 있으면 좋은 feature(특징,column))을 추가하는 의미가 아닐까?)
XGBoost는 tabular data(2차원 행렬 데이터)에서 돌아갑니다.
+) tabular data EX: DataFrame type in Pandas. 이미지나 비디오에는...ㅠ
XGBRegressor에는 다양한 parameter들이 있지만 차차 배워봅시다.

1. 일단 scikit-learn으로 model을 fit하고 build해봅시다.
from xgboost import XGBRegressor
my_model = XGBRegressor()
my_model.fit(X_train, y_train)
2. 예측을 만들어보고 model을 평가해봅시다.
from sklearn.metrics import mean_absolute_error
predictions = my_model.predict(X_valid)
print("Mean Absolute Error: " + str(mean_absolute_error(predictions, y_valid)))
Parameter Tuning
XGBoost에는 정확도와 training 속도를 급격하게 올려주는 몇가지 parameter가 있습니다.
1. n_estimators
위에 기술된 modeling cycle을 몇 회할 지 정해줌
이는 ensemble에 포함된 model의 수와 동일
보통 100-1000 사이 값을 이용하지만, "learning_rate" parameter에 따라 크게 달라짐
너무 낮은 값이면 underfitting 발생
training data와 test data 둘 다로부터 부정확한 예측을 나오게 함.
너무 높은 값이면 overfitting 발생
training data에서는 정확한 예측을 해주지만 test data에서 그렇지 않음. (우리가 고민해야 할 부분)
my_model = XGBRegressor(n_estimators=500)
my_model.fit(X_train, y_train)
+) Exercise에서... 흑
model의 tree 수를 대폭 줄이는 것 또한 방법이라네요ㅠ
# Define the model
my_model_3 = XGBRegressor(n_estimators=1)
# Fit the model
my_model_3.fit(X_train, y_train)
# Get predictions
predictions_3 = my_model_3.predict(X_valid)
# Calculate MAE
mae_3 = mean_absolute_error(predictions_3, y_valid)
print("Mean Absolute Error:" , mae_3)
2. early_stopping_rounds + eval_set (valid data를 넣어 validation score 계산)
최적의 n_estimators값을 자동적으로 찾아줌.
초기에 멈추면, validation score가 더 이상 나아지지 않을 때, model의 반복을 멈출 수 있음.
n_estimators값만큼 반복하지 않더라도, 강제적으로 멈출 수 있다?
그러니 n_estimators에는 높은 값을 넣은 뒤 early_stopping_rounds로 최적의 반복 중지 타이밍을 잡자
때때로 validation score가 개선되지 않는 single round가 발생할 수 있기에(그곳에 갇혀버릴 수 있기에ㅠ)
중지하기 전에 악화되는 round를 몇 회 지속할 지 정해야합니다.
early_stopping_rounds=5 를 많이들 사용.
validation score가 악화되는 5회 때 중지시킴.
my_model = XGBRegressor(n_estimators=500)
my_model.fit(X_train, y_train,
early_stopping_rounds=5,
eval_set=[(X_valid, y_valid)],
verbose=False)
3. learning_rate
그저 각 모델로부터의 예측을 더하기 전, 그 예측마다 작은 수를 곱해줄 수 있습니다.
그 작은 수가 바로 learning_rate 입니다.
그저 많은 tree를 ensemble에 넣는 건 그다지 좋은 효율을 내지 않습니다.
그렇기에 overfitting이 나지 않는 선에서 n_estimators를에 높은 값을 넣으며, early_stopping으로 더 적절한 tree의 수를 결정합니다.
일반적으로 small learning rate와 큰 수의 estimators는 좀 더 정확한 XGBoost model를 산출합니다.
그러나 이또한 모델이 훈련하는 시간이 더 걸리게 합니다. 더 많은 cycle을 반복하기 때문이죠.
그래서 보통 XGBoost에서 learning_rate=0.1로 정합니다.
'
예제에서 learning_rate를 바꾸어 가며 산출되는 값을 한 번 봐보세요.
my_model = XGBRegressor(n_estimators=1000, learning_rate=0.05)
my_model.fit(X_train, y_train,
early_stopping_rounds=5,
eval_set=[(X_valid, y_valid)],
verbose=False)
4. n_jobs ( use when dataset is large)
n_jobs는 결과 모델를 최적화하는데, validation score을 높이기 위해 쓰는게 아닙니다.
fitting에 소요되는 시간을 최적화해줄 뿐이죠.
runtime을 고려해봐야하는 아주 큰 dataset에서는, model를 더 빠르게 build하기 위해 parallelism을 사용.
이는 "n_jobs" parameter로 정하며, 자신의 machine의 core(cpu)의 수와 일치
smaller dataset에선 도움 안 됨
my_model = XGBRegressor(n_estimators=1000, learning_rate=0.05, n_jobs=4)
my_model.fit(X_train, y_train,
early_stopping_rounds=5,
eval_set=[(X_valid, y_valid)],
verbose=False)
'Machine Learning > [Kaggle Course] ML (+ 딥러닝, 컴퓨터비전)' 카테고리의 다른 글
| [Kaggle Course] A Single Neuron _ Define a linear model (0) | 2020.12.17 |
|---|---|
| [Kaggle Course] How to prevent "Data Leakage" (0) | 2020.11.01 |
| [Kaggle Course] Cross-Validation(교차검증) (0) | 2020.10.23 |
| [Kaggle Course] Pipelines + How to make and submit CSV in Kaggle (0) | 2020.10.21 |
| [Kaggle Course] Categorical Variables (0) | 2020.10.12 |