Machine Learning/초단순정리
Attention - Transformer Architecture
WakaraNai
2021. 12. 22. 09:49
728x90
반응형
convolutional 방식은 구조적으로 바로 옆 픽셀이 아니라면 볼 수 없음
즉 전체적인 이미지를 고려하는 것이 어려움
그래서 attention을 이용
각 픽셀의 중요도를 또다른 행렬로 표현하여
곱셈을 통해 중요한 지점을 부각시키기
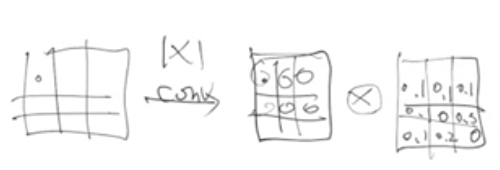
Key, Query, Value
key와 query의 유사도를 찾기 위해

를 구한 뒤
softmax를 적용하여 0~1로 치환
이렇게 나온 attention map을 value에 곱해서
어떤 녀석이 더 중요한지 알아냄
Attention은
GPT-3, BERT, Transformer 등 다양히 이용
Transformer Model Architecture

Encoder Block


Decoder Block

728x90
반응형