[논문][Activation] Mish Activation Function
논문 주소
Mish: A Self Regularized Non-Monotonic Activation Function
https://arxiv.org/abs/1908.08681
Mish: A Self Regularized Non-Monotonic Activation Function
We propose $\textit{Mish}$, a novel self-regularized non-monotonic activation function which can be mathematically defined as: $f(x)=x\tanh(softplus(x))$. As activation functions play a crucial role in the performance and training dynamics in neural networ
arxiv.org

순서대로, identity function, tanh, softplus를 조합한 것
Activation Function 중의 하나로 relu보다 나은 것 중 하나라고 함
확실히 Computer vision 논문 보다 훨씬 눈에 잘 들어온다
사진부터 보다 보니 글을 읽게 되고 대략적으로 다 읽어버렸다.
앞으로도 그래프나 사진 중심으로 시작해야지..
ReLU는 tanh와 sigmoid보다 성능이 뛰어나고 안정적이라고 평가받는다. 하지만 음수 입력값을 0으로 뭉개버려서 발생하는 gradient loss 단점이 있다. 이를 보완하기 위해 Leaky ReLU, ELU, SELU, Swish 등이 나왔고 대략적인 식은 f(x) = x*sigmoid(βx). 특히 swish는 relu보다 부드럽고 연속적인 모습을 띈다.

그럼 여기서 제기하는 Mish는!!
novel self regularized non-monotonic activation function inspired by the self gating property of Swish.
Swish의 자기 게이트 속성에서 영감을 받은 새로운 자기 정규화된 비 단음 활성화 함수...?

Mish, ReLU, SoftPlus, Swish를 비교한 그래프
(a) Mish와 Swish는 음수에서 약간 꺼졌다가 너무 큰 음수에서만 0으로 수렴하도록 보완 ( small negative weights)
(b) Mish와 Swish를 미분했을 때의 그래프
미분했을 때의 식

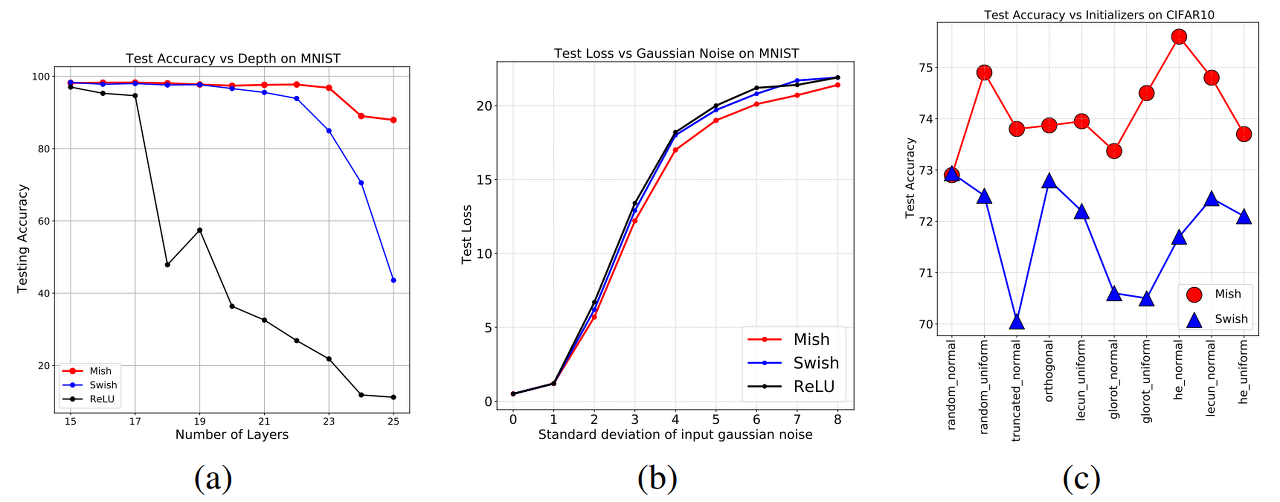
(a) Mish, ReLU, Swish에 대해 신경망의 깊이가 깊어질 수록 변하는 test accuracy
(c) 서로 다른 weight initialization 전략에서의 test accuracy를 Mish와 Swish에 대해 봤을 때
- truncated_normal, glorot_normal, glorot_uniform, he_normal에서 'Mish'가 3-4% 우세하다

ReLU의 출력 지형은 Mish의 출력 지형의 부드러운 프로필에 비해 많은 급격한 전환을 가지고 있다.
부드러운 출력 환경을 통해 부드러운 손실 환경일 수록 좋은 것.
그럼으로 Mish는 보다 쉬운 최적화와 더 나은 일반화에 도움이 된다.
그림을 보면, mish를 장착한 ResNet20의 손실 상황은 ReLU 및 swish에 비해 훨씬 부드럽고 컨디셔닝되어 있다.
Mish는 넓은 최소값을 가지고 있기에,
ReLU 및 Swish에 비해 일반화를 개선할 수 있다.
또한, ReLU와 Swish가 장착된 네트워크에 비해 가장 낮은 손실을 얻었으며,
따라서 손실 표면에 대한 Mish의 사전 조절 효과를 검증하였다.
Statistical Analysis
: Statistical results of different activation functions
on image classification of CIFAR10 dataset
using a Squeeze Net for 23 runs.

CIFAR-10
Comparison between Mish, Swish, and ReLU activation functions
based on test accuracy on image classification of CIFAR-10
across various network architectures.
다른 activation과 0.5-1% 차이...?

with MS-COCO Object Detection
대충 보니, CSP-DarkNet-53과 CSP-DarkNet-53+PANet+SPP 모델 속에 쓰인 ReLU를 싹다 Mish로 교체하여 시도함.
Transfer Learning이 아니므로 나도 시도할 수 있는 방법인지에 대해서 의문. 시도해보니 0.4~0.5% 발전했다고...
여기선 CutMix, Mosaic, Self Adversarial Training(SAT), Dropblock regularization, Label Smoothing 등의 data augmentation과 함께 검증해봤다고 함
mish는 identity function, tanh, softplus를 조합한 것인 만큼 많이 복잡하여 그만큼 computational cost가 크다.
그래서 Mish는 CUDA 기반으로 돌려야 좋은 성적을 보여서 슬프다. (RTX-2070 GPU에서 100번 돌린 결과)

Mish는 미분 계산을 포함하는 backward propagation을 가속화하는
TanH 항의 지수 등가(exponential equivalent) 값을 사용하여 추가로 최적화할 수 있다.